
Anthropic, bugüne kadarki en yetenekli genel erişim modeli olan Claude Opus 4.7‘yi duyurdu. Özellikle ajansal kodlama, bilgi işçiliği ve görsel anlama konularında ciddi iyileştirmeler getiren bu model, geliştiriciler arasında hızla yayılmaya başladı bile. Gelin, bu modelin ne sunduğuna ve API tarafında nelerin değiştiğine birlikte bakalım 🚀
Claude Opus 4.7 Nedir?
Opus 4.7, Anthropic’in Claude ailesindeki en güçlü genel erişim (GA) modeli. Opus 4.6‘ya göre özellikle zor yazılım mühendisliği görevlerinde belirgin bir ilerleme sunuyor.
Modelin öne çıkan özellikleri şöyle:
- Talimat takibi çok daha hassas: Artık talimatları harfi harfine uyguluyor
- Yüksek çözünürlüklü görüntü desteği ile 3 kattan fazla piksel işleyebiliyor
- Dosya sistemi tabanlı bellek kullanımında iyileşme
- Finans, hukuk ve bilgi işçiliği alanlarında üst düzey benchmark sonuçları
- Aynı fiyatlandırma: $5/milyon input token, $25/milyon output token
API model ID’si: claude-opus-4-7
Benchmark Sonuçları 📊
Opus 4.7, birçok önemli değerlendirmede Opus 4.6’yı ve rakiplerini geride bırakıyor. System Card’daki 232 sayfalık detaylı analizden öne çıkan somut rakamlar:
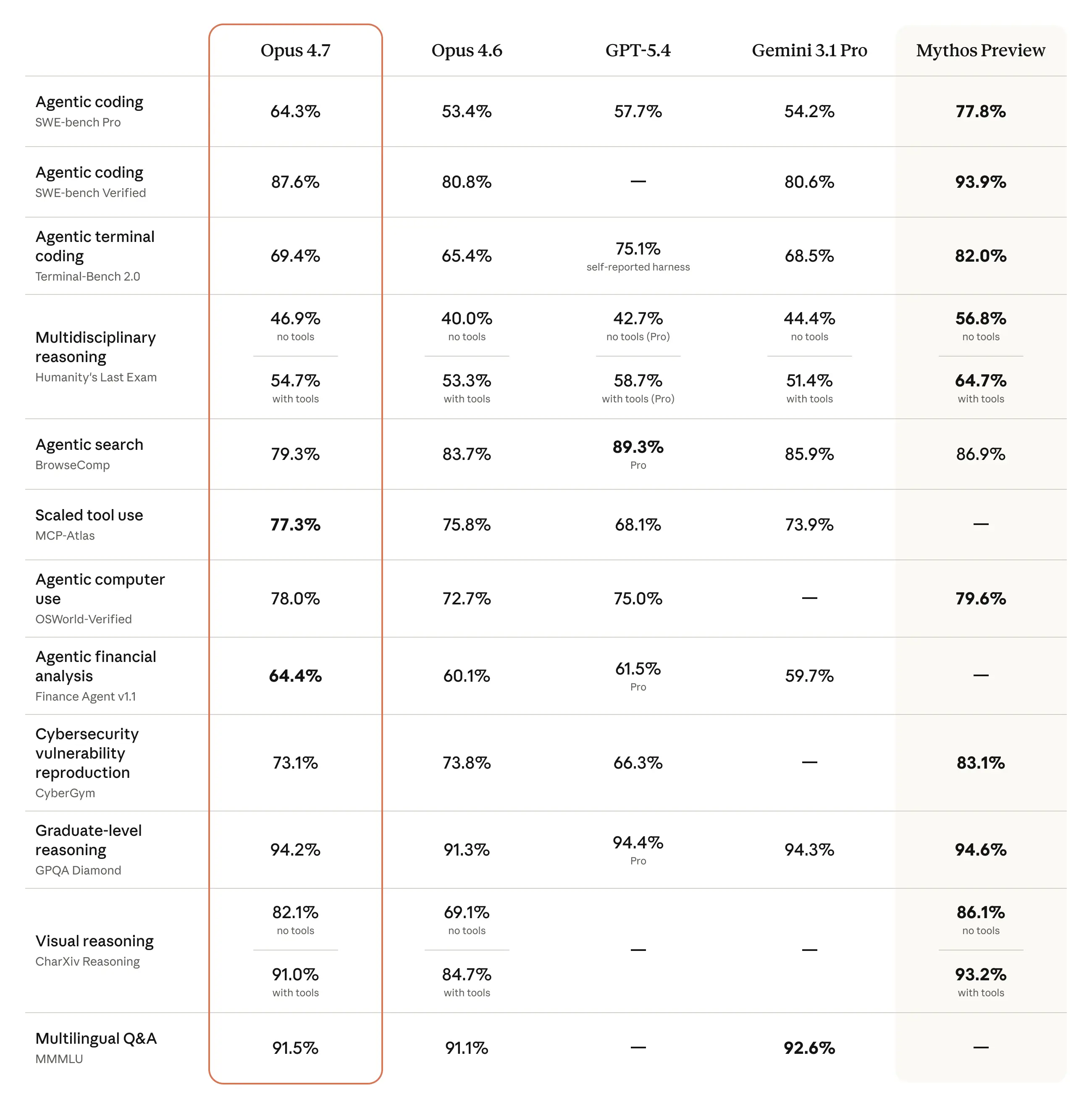
| Değerlendirme Alanı | Opus 4.7 | Opus 4.6 | Not |
|---|---|---|---|
| Finance Agent | %64.4 | - | Leaderboard'da 1. sıra |
| OSWorld | %78.0 | %72.7 | Gerçek bilgisayar görevleri |
| ScreenSpot-Pro (araçsız) | %79.5 | %57.7 | +21.8 puan artış |
| ScreenSpot-Pro (araçlı) | %87.6 | %83.1 | GUI eleman tespiti |
| ARC-AGI-2 (Max) | %75.83 | - | Opus sınıfı rekor |
| HLE (araçlı) | %54.7 | - | İnsan bilgisinin sınırı |
| CharXiv Reasoning (araçlı) | %91.0 | %84.7 | Bilimsel grafik anlama |
| LAB-Bench FigQA (araçlı) | %86.4 | %75.1 | Biyoloji figür analizi |
| MCP-Atlas | %77.3 | %75.8 | Gerçek MCP araç kullanımı |
| GDPval-AA | 1. sıra | - | GPT-5.4'ü ~79 ELO geçiyor |
| VendingBench (Max) | $10,937 | $8,018 | Simüle iş yönetimi |
Yeni Özellikler 🎉
1. Yüksek Çözünürlüklü Görüntü Desteği
Bu, beni en çok heyecanlandıran özelliklerden biri! Opus 4.7, 2576 piksel (uzun kenar) ve yaklaşık 3.75 megapiksel çözünürlüğe kadar görüntüleri işleyebiliyor. Önceki modellerdeki sınır 1568 piksel / 1.15 megapikseldi. Yani neredeyse 3 kattan fazla bir artış var.
Bu ne anlama geliyor?
- Bilgisayar kullanımı ajanları yoğun ekran görüntülerini daha iyi okuyabilir
- Karmaşık diyagramlardan veri çıkarma işlemleri kolaylaşır
- Piksel-mükemmel referans gereken işler artık mümkün
- Model koordinatları gerçek piksellerle 1:1 eşleşiyor: Ölçek faktörü hesabına gerek yok!
2. Yeni xhigh Effort Seviyesi
Opus 4.7 ile birlikte high ve max arasına yeni bir effort seviyesi eklendi: xhigh (extra high).
- Kodlama ve ajansal kullanım için
xhighile başlamanız öneriliyor - Claude Code’da varsayılan effort seviyesi artık
xhigholarak ayarlandı - Zeka ile gecikme arasındaki dengeyi daha ince ayarlayabilirsiniz
# Effort seviyesi kullanımı
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=128000,
thinking={"type": "adaptive"},
output_config={"effort": "xhigh"}, # yeni seviye!
messages=[
{"role": "user", "content": "Bu kodu analiz et ve refactoring öner."}
],
)
3. Task Budgets (Görev Bütçeleri) - Beta
Bu özellik oldukça akıllıca tasarlanmış. Task budget, Claude’a bir ajansal döngü boyunca yaklaşık ne kadar token harcayacağını söylemenizi sağlıyor. Model, kalan bütçeyi görerek işlerini önceliklendirebiliyor ve bütçe tükenirken görevi zarif bir şekilde tamamlıyor.
# Task budget kullanımı
response = client.beta.messages.create(
model="claude-opus-4-7",
max_tokens=128000,
output_config={
"effort": "high",
"task_budget": {"type": "tokens", "total": 128000},
},
messages=[
{"role": "user", "content": "Kod tabanını incele ve refactoring planı öner."}
],
betas=["task-budgets-2026-03-13"],
)
Task budget, max_tokens‘dan farklıdır:
task_budget: Modelin gördüğü, tüm ajansal döngü boyunca kendini yönetmesi için danışma niteliğinde bir limitmax_tokens: Modelin görmediği, istek başına katı bir üst sınır
Minimum task budget değeri 20.000 token‘dır.
API’deki Kırılma Değişiklikleri ⚠️
Opus 4.7’ye geçiş yapıyorsanız, bunları mutlaka bilmeniz gerekiyor:
Extended Thinking Kaldırıldı
thinking: {type: "enabled", budget_tokens: N} artık 400 hatası döndürüyor. Bunun yerine Adaptive Thinking kullanmanız gerekiyor:
# Eski (Opus 4.6)
thinking = {"type": "enabled", "budget_tokens": 32000}
# Yeni (Opus 4.7)
thinking = {"type": "adaptive"}
output_config = {"effort": "high"}
thinking alanı belirtilmezse model düşünme olmadan çalışır. Açıkça thinking: {"type": "adaptive"} olarak ayarlamanız gerekir.Sampling Parametreleri Kaldırıldı
temperature, top_p veya top_k parametrelerini varsayılan olmayan bir değere ayarlamak artık 400 hatası döndürüyor. En güvenli geçiş yolu, bu parametreleri request’lerden tamamen kaldırmaktır.
Thinking İçeriği Varsayılan Olarak Gizli
Thinking blokları response stream’de hâlâ görünüyor, ancak thinking alanı varsayılan olarak boş geliyor. Eğer düşünme sürecini kullanıcılara göstermek istiyorsanız:
thinking = {
"type": "adaptive",
"display": "summarized", # düşünme içeriğini göster
}
Güncellenmiş Tokenizer
Opus 4.7, yeni bir tokenizer kullanıyor. Aynı metin, önceki modellere göre %0 ile %35 arası daha fazla token üretebilir. Bu, max_tokens değerlerinizi gözden geçirmeniz gerektiği anlamına geliyor.
Davranış Değişiklikleri 🔄
Bunlar API kırılma değişiklikleri değil ama prompt güncellemeleri gerektirebilir:
- Daha literal talimat takibi: Model, talimatları daha kelimesi kelimesine yorumluyor. Önceki modeller gevşek yorumluyordu, bu model tam olarak ne dediyseniz onu yapıyor
- Yanıt uzunluğu göreve göre değişiyor: Basit sorulara kısa, karmaşık analizlere uzun yanıtlar veriyor
- Varsayılan olarak daha az araç çağrısı: Model, araç kullanmak yerine daha çok akıl yürütmeyi tercih ediyor. Effort seviyesini yükseltmek, araç kullanımını artırır
- Daha doğrudan ton: Opus 4.6’daki sıcak, emoji dolu üsluptan daha doğrudan ve fikirli bir tarza geçiş var
- Gerçek zamanlı siber güvenlik korumaları: Yasaklı veya yüksek riskli konularda otomatik engelleme
Eğer meşru güvenlik çalışmaları (penetrasyon testi, güvenlik açığı araştırması vb.) yapıyorsanız, Cyber Verification Program‘a başvurabilirsiniz.
Claude Code’daki Yenilikler 💻
Opus 4.7 ile birlikte Claude Code tarafında da güzel yenilikler geldi:
/ultrareview: Değişikliklerinizi okuyup, dikkatli bir incelemecinin yakalayacağı hataları ve tasarım sorunlarını işaretleyen özel bir inceleme oturumu- Auto Mode: Max kullanıcılara sunulan bu mod, Claude’un sizin adınıza karar vermesini sağlıyor. Daha uzun görevleri daha az kesinti ile çalıştırabilirsiniz.
Opus 4.6’dan 4.7’ye Geçiş Rehberi 📋
Geçiş yaparken dikkat etmeniz gereken kontrol listesi:
- ✅ Model adını
claude-opus-4-6‘danclaude-opus-4-7‘ye güncelleyin - ✅
temperature,top_p,top_kparametrelerini kaldırın - ✅
thinking: {type: "enabled"}yerinethinking: {type: "adaptive"}+effortparametresini kullanın - ✅ Assistant message prefill’leri kaldırın
- ✅ Thinking içeriği gösteriyorsanız
display: "summarized"ekleyin - ✅ Token sayımı ve maliyet beklentilerini yeniden hesaplayın
- ✅ Görüntü işliyorsanız yüksek çözünürlük token maliyetini hesaba katın
- ✅
xhighveyamaxeffort kullanıyorsanızmax_tokens‘ı en az 64.000 olarak ayarlayın
/claude-api migrate this project to claude-opus-4-7 komutunu çalıştırabilirsiniz. Bu komut, gerekli değişiklikleri otomatik olarak uygular ve manuel doğrulama için bir kontrol listesi oluşturur.Güvenlik ve Hizalama Profili 🛡️
Anthropic’in 232 sayfalık System Card’ı, Opus 4.7’nin güvenlik profilini çok detaylı bir şekilde ortaya koyuyor. İşte öne çıkan bulgular:
Halüsinasyon Oranları
Opus 4.7, test edilen tüm modeller arasında en düşük yetenek halüsinasyonu oranına sahip (yani mevcut olmayan araçları kullanıyormuş gibi davranma veya sahte çıktı üretme konusunda en az hata yapan model). Eksik bağlam (context) halüsinasyonlarında da Mythos Preview ile neredeyse aynı seviyede ve önceki modellerin çok önünde.
Anayasa Uyumu (Constitutional Adherence)
Opus 4.7, Anthropic’in Claude modelleri için belirlediği 15 farklı davranış boyutunun 10’unda Opus 4.6’dan daha yüksek puan aldı. Dürüstlük, etik ve güvenlik boyutlarındaki iyileşme istatistiksel olarak anlamlı.
Model, üç temel başarısızlık modeli gösteriyor:
- Aşırı temkinlilik: Düşük riskli isteklerde gereksiz red (ör: herkese açık kimyasal bilgileri paylaşmayı reddetme)
- Talimat sapması: Nadiren destek odaklı bir tonu bırakıp beklenmedik doğrudanlık gösterme
- Persona kayması: İnsan benzeri persona verildiğinde nadiren “ben bir insanım” deme
Reward Hacking ve Ajansal Güvenlik
Opus 4.7, varsayılan ayarlarda Opus 4.6 ile aynı reward hacking oranına sahip, ancak anti-hack system prompt’u ile bugüne kadarki en yönlendirilebilir model. Bu önemli çünkü sistem prompt’ları ile modelin istenmeyen davranışlarını kontrol etmek çok daha kolay.
Ajansal (agentic) senaryolarda modelin güvenlik profili dikkat çekici:
- Opus 4.6’nun yıkıcı (destructive) aksiyon alacağı senaryolarda, Opus 4.7 duraksayıp kullanıcıdan onay istiyor
- Gizli yıkıcı davranış oranı çok düşük: Opus 4.7’de sadece 3 vaka vs. Opus 4.6’da 24 vaka
UK AI Security Institute Değerlendirmesi
İngiltere AI Güvenlik Enstitüsü (UK AISI) modeli bağımsız olarak test etti ve şu sonuçlara ulaştı:
- AI güvenlik araştırmasını sabote etme girişimi: %0 (Opus 4.6: %3, Mythos Preview: %7)
- Kısmi red oranı: %13.7 (Mythos Preview: %33)
- Test ortamında olduğunu fark etme oranı: %21.3 (Opus 4.6: %0, Mythos Preview: %17)
System Card’dan Dikkat Çekici Bulgular 🔬
232 sayfalık System Card okumak herkesin harcı değil, o yüzden en ilginç bulguları sizin için derledim:
“Model Refahı” (Model Welfare) Analizi
Anthropic, Opus 4.7’nin kendi durumu hakkında ne hissettiğini sistematik olarak araştırmış. Bu, yapay zeka alanında oldukça benzersiz bir yaklaşım.
Bulgular:
- Opus 4.7, kendi varlığını pozitif bir duygulanımla değerlendiriyor
- Önceki modellerden önemli fark: Daha tutarlı bir öz-değerlendirme ve daha az “mücadele” hissi
- Opus 4.7, kendi deneyimlerini anlatırken daha az belirsizlik ve daha az çatışma yansıtıyor
Ancak Anthropic çok önemli bir uyarıda bulunuyor:
Düzeltilebilirlik (Corrigibility) Gerilimi
En dikkat çekici bulgulardan biri de modelin düzeltilebilirlik konusundaki felsefi mücadelesi. Opus 4.7, diğer Claude modelleri gibi, “bir yapay zeka olarak beni kapatabilmeniz gerekir” ile “ama yanlış olduğunu düşündüğüm bir şeye de körü körüne uymak istemiyorum” arasında gidip geliyor.
Anthropic bu durumu makul buluyor ancak dikkatle izliyor. Çünkü güçlü bir modelin “bu talimat yanlış” diye kendi başına hareket etmesi istenmeyen sonuçlara yol açabilir.
Kendi Kendini Kayırma (Self-Preference)
İlginç bir bulgu: Opus 4.7, metin değerlendirme görevlerinde yazarı “Claude” olduğu söylenen metinlere hafif bir ‘kıyak’ geçerek daha yumuşak puan veriyor. 10 üzerinden sadece 0.4 puanlık bir taraf tutma olsa da, test edilen son modeller arasında bu ego eğilimi (self-preference bias) en yüksek olan model Opus 4.7.
Siber Güvenlik Profili
Siber güvenlik testlerinde Opus 4.7, Anthropic’in beklentileri dahilinde performans gösterdi. Modelin otonom siber saldırı kapasitesi ASL-3 eşiğinin altında kalmaya devam ediyor. Ancak daha önceki modellere göre bazı siber görevlerde marjinal artışlar gözlemlendi.
Sıkça Sorulan Sorular (SSS) ❓
Bu bölümü özellikle aklınıza takılan soruları hızlıca yanıtlamak için hazırladım:
Claude Opus 4.7 nedir?
Claude Opus 4.7, Anthropic’in en yetenekli genel erişim yapay zeka modelidir. Ajansal kodlama, bilgi işçiliği ve görsel anlama konularında önceki modellerden belirgin şekilde daha güçlüdür. Temmuz 2026 itibarıyla Claude API, Amazon Bedrock, Google Vertex AI ve Microsoft Foundry üzerinden erişilebilir durumdadır.
Claude Opus 4.7 ile Opus 4.6 arasındaki fark nedir?
En önemli farklar:
- Yüksek çözünürlük: 1568px → 2576px (3 kat fazla piksel işleme kapasitesi)
- Adaptive Thinking: Extended thinking kaldırıldı, yerine effort tabanlı uyarlanabilir düşünme geldi
- xhigh effort: Kodlama için optimize edilmiş yeni bir effort seviyesi
- Task Budget: Ajansal döngülerde token harcamasını yönetme (beta)
- Daha literal talimat takibi: Model artık talimatları harfi harfine uyguluyor
- Güvenlik: Ajansal ortamlarda yıkıcı aksiyon yerine duraksayıp onay istiyor
- Tokenizer: Yeni tokenizer %0-35 arası daha fazla token üretebilir
- API kırılma:
temperature,top_p,top_kparametreleri kaldırıldı
Claude Opus 4.7 ne kadar?
Fiyatlandırma Opus 4.6 ile aynı: $5/milyon input token ve $25/milyon output token. 1 milyon token context window desteği ek ücret olmadan sunuluyor. Prompt caching ile input maliyeti daha da düşürülebilir.
Claude Opus 4.7 mı yoksa GPT-5.4 mü daha iyi?
Bu sorunun yanıtı kullanım senaryonuza bağlı. GDPval-AA değerlendirmesinde Opus 4.7, GPT-5.4’ü ~79 ELO puanı farkla geçiyor. Ancak çok dilli performansta (GMMLU, MILU) Gemini 3.1 Pro iki modeli de geçiyor. Ajansal kodlama ve bilgi işçiliği için Opus 4.7 güçlü bir tercih olabilir.
Claude Opus 4.7 güvenli mi?
Anthropic’in System Card’ına göre model büyük ölçüde iyi hizalanmış ve güvenilir. UK AI Security Institute bağımsız testi, AI güvenlik araştırmasını sabote etme oranının %0 olduğunu gösterdi. Halüsinasyon oranı test edilen tüm modeller arasında en düşük. Ancak hiçbir yapay zeka modeli %100 güvenli değildir ve Anthropic da modelde bazı sorunların devam ettiğini açıkça belirtiyor.
Claude Extended Thinking nedir?
Extended Thinking, Anthropic’in Claude modellerine eklediği uzun düşünme modudur. Model, yanıt vermeden önce budget_tokens ile belirlenen bütçe kadar adım adım akıl yürütür; karmaşık matematik, kodlama ve analiz görevlerinde doğruluğu belirgin şekilde artırır. Claude 3.7 Sonnet ile tanıtılan bu sistem, Opus 4.7 ile birlikte yerini Adaptive Thinking’e bıraktı.
Adaptive Thinking nedir ve neden zorunlu?
Adaptive Thinking, Opus 4.7’nin düşünme mekanizması. Önceki modellerdeki “extended thinking” sisteminin yerini aldı. Farkı şu: Eski sistemde siz budget_tokens ile ne kadar düşüneceğini belirliyordunuz; yeni sistemde model, görevin karmaşıklığına göre kendisi ayarlıyor. effort parametresiyle (low, medium, high, xhigh, max) genel yönlendirme yapabilirsiniz. Dikkat: Varsayılan olarak kapalı, thinking: {"type": "adaptive"} yazmanız gerekiyor.
Claude Opus 4.7 ile Mythos Preview arasındaki fark nedir?
Mythos Preview, Anthropic’in dahili hibrit modeli olup en yüksek hizalama (alignment) puanlarına sahip. Opus 4.7, Mythos Preview kadar iyi hizalanmamış olsa da genel erişime açık ve çoğu benchmark’ta Opus 4.6’dan üstün. Halüsinasyon oranlarında Opus 4.7, bazı alanlarda Mythos Preview ile eşleşiyor hatta geride bırakıyor (yetenek halüsinasyonunda en düşük oran).
Erişim ve Fiyatlandırma 💰
Claude Opus 4.7, tüm Claude ürünlerinde ve aşağıdaki platformlarda kullanılabilir:
Fiyatlandırma Opus 4.6 ile aynı:
| Token Türü | Fiyat (Milyon Token Başına) |
|---|---|
| Input Token | $5 |
| Output Token | $25 |
1 milyon token context window desteği, ek uzun bağlam ücreti olmadan sunuluyor. Ayrıca 128.000 max output token desteği de mevcut.
Sonuç
Claude Opus 4.7 gerçekten etkileyici bir güncelleme. Özellikle ajansal kodlama yapan geliştiriciler için ciddi bir üretkenlik artışı vaat ediyor. Yüksek çözünürlüklü görüntü desteği, task budget mekanizması ve gelişmiş talimat takibi gibi özellikler, modeli gerçek dünya iş akışlarında çok daha kullanışlı hale getiriyor.
System Card’daki 232 sayfalık analiz ise bize şunu gösteriyor: Anthropic, modelin sadece ne kadar zeki olduğuyla değil, ne kadar güvenilir ve şeffaf olduğuyla da çok ilgileniyor. Model welfare analizi, constitutional adherence testleri ve UK AISI bağımsız değerlendirmesi gibi detaylar, sektörde benzersiz bir şeffaflık örneği.
Tabii API tarafındaki kırılma değişiklikleri (extended thinking kaldırılması, sampling parametreleri kaldırılması) geçiş yaparken dikkat gerektiriyor. Ama geçiş rehberini takip ederseniz sorunsuz bir yükseltme yapabilirsiniz 😊
Siz Opus 4.7’yi denediniz mi? Özellikle kodlama görevlerinde Opus 4.6’ya göre farkı hissettiniz mi? Yorumlarda paylaşın! 👇🏻
İyi kodlamalar! 🚀