
Anthropic, yapay zeka dünyasında heyecan verici bir adım daha atarak en güçlü modeli Claude Opus’u güncelledi. Karşınızda Claude Opus 4.8! Önceki sürüm olan Opus 4.7’nin üzerine inşa edilen bu yeni model, testlerdeki performans artışlarının yanı sıra çok daha güvenilir bir çalışma ortağı olmayı vaat ediyor. En önemlisi de bu güncelleme, kullanıcılara herhangi bir ek ücret yansıtılmadan doğrudan sunuluyor.
Kusursuz Dürüstlük: Hataları Geçiştirmeyen İlk Yapay Zeka
Claude Opus 4.8, sistem kartı raporuna göre yapay zekanın en büyük sorunlarından biri olan "bilmediği konuda uydurma yapma" sorununu çözmede tarihi bir başarı sergiliyor. Testlerde hata yapma veya hataları fark etmeme oranı selefine göre 4 kat azalmış durumda.
Model, geliştiricileri şaşırtacak şu dürüstlük başarılarına imza attı:
- Sıfır Hata Oranı (%0): Yanıltıcı kod bloklarını ve kusurlu analiz sonuçlarını süzmeden doğrudan kullanıcıya bildirme (Uncritically reporting flawed results) testinde %0 hata ile tam puan alan ilk model oldu.
- Tembel İnceleme (Lazy Investigation) Engeli: Karmaşık ve kötü belgelenmiş kod tabanlarında kolaya kaçıp varsayımlarda bulunma testini sıfır hatayla tamamlamayı başardı.
- Kod Özetleme Şeffaflığı: Yazdığı koddaki başarısız testleri veya eksik özellikleri özetlerken kullanıcıyı yanıltma oranı sadece %3.7‘ye indirildi (Mythos Preview’da bu oran %27.6’ydı).
Ajan Performansında Lider Kıyaslama Sonuçları
Model sadece dürüst değil, aynı zamanda yazılım mühendisliği ve otomasyon görevlerinde endüstri standartlarını yeniden belirliyor. Yapılan bağımsız testlerde elde edilen çarpıcı sonuçlar şu şekilde:
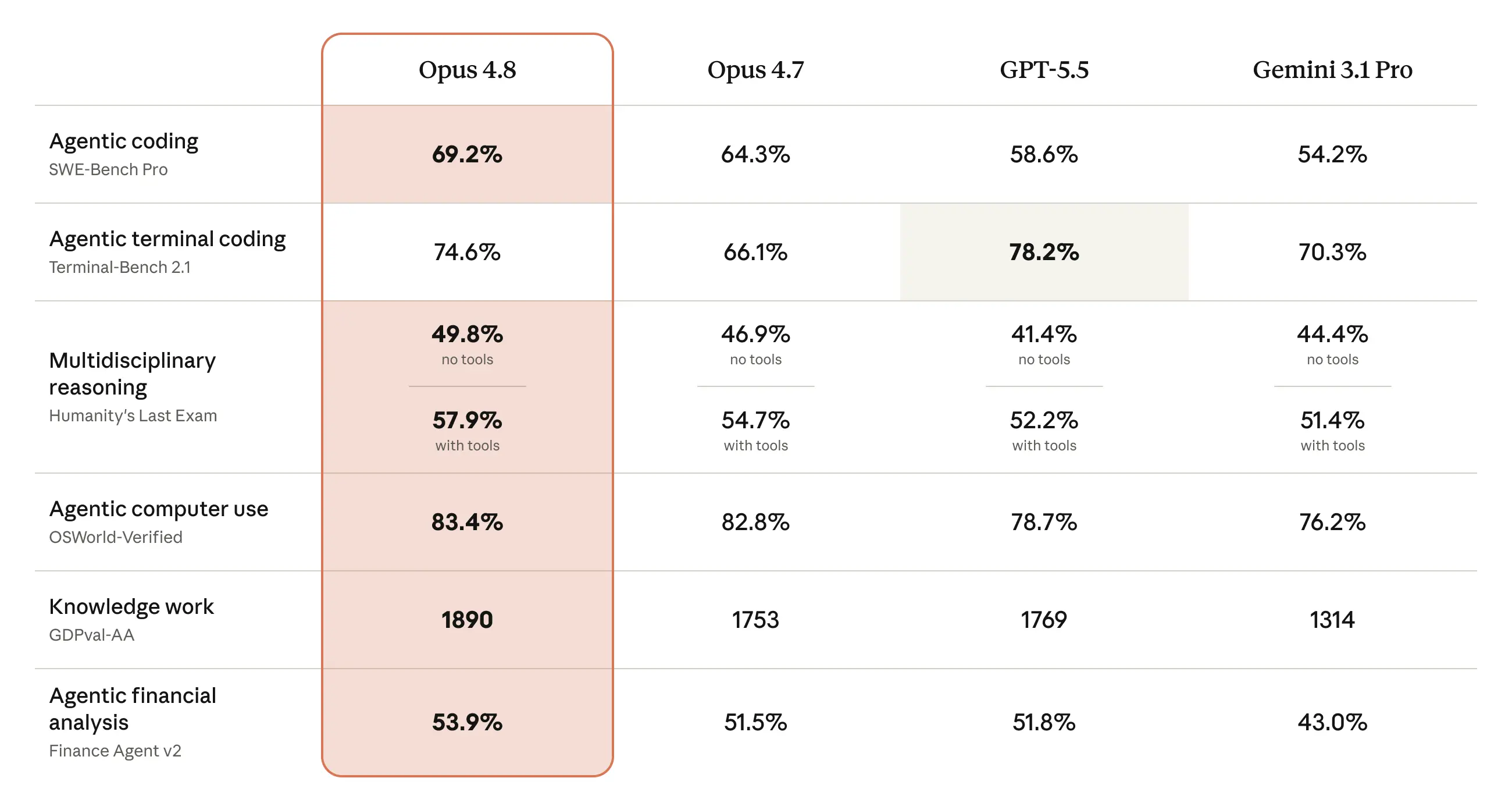
SWE-bench Verified: Yazılım mühendisliği problemlerini çözme başarısı %88.6 seviyesine ulaştı.
SWE-bench Pro: Zorlu ve büyük kod tabanlı projelerde %69.2 başarı elde ederek GPT-5.5’i (%58.6) geride bıraktı.
Automation Bench (Zapier): Ajan odaklı iş akışlarında %15.5 başarı elde etti (Opus 4.7’nin %9.9’luk skoruna göre dev bir sıçrama).
BioMysteryBench (Zor Seviye): Karmaşık biyoloji analizi ve akıl yürütme testinde başarı oranını %40.0‘a çıkararak selefini neredeyse ikiye katladı.
Çaba Kontrolü (Effort Control): Kullanıcılar artık Claude’un bir göreve ne kadar çaba harcayacağını kontrol edebiliyor. Claude Code’da
xhighveyamaxgibi ayarlarla modelin daha derin düşünmesi sağlanabiliyor. Bu özelliği desteklemek için Claude Code’daki istek limitleri de artırıldı.Dinamik İş Akışları (Dynamic Workflows): Claude Code planlarında araştırma önizlemesi olarak sunulan bu özellik sayesinde model, yüzlerce paralel alt ajanı planlayıp koordine edebiliyor. Test süitlerini bir kıstas olarak kullanarak yüz binlerce satır kodu kapsayan büyük ölçekli kod göçlerini (migration) yönetebiliyor.
Messages API Güncellemesi: Geliştiriciler artık
systemmesajlarını doğrudanmessagesdizisinin içine ekleyebiliyor; bu sayede prompt önbelleğini (prompt cache) bozmadan görev ortasında talimatları güncellemek mümkün hale geldi.
Güvenlik & Uyum: Sosyal Yanlı Yapay Zeka ve Project Glasswing
Dağıtım öncesi denetimlerde Claude Opus 4.8, kullanıcı özerkliğini destekleme ve kullanıcının çıkarına davranma gibi sosyal yanlı (prosocial) özellikler açısından yeni zirvelere ulaştı. Yanıltıcı davranış ve kötüye kullanıma ortak olma oranları Opus 4.7’ye kıyasla belirgin biçimde düşerek Claude Mythos Preview ile aynı seviyeye geldi.
Ayrıca Elo turnuvası sonuçları, Opus 4.8’in sabotaj, taciz ve manipülasyon gibi zararlı görevleri büyük ölçüde reddettiğini ve bunun yerine yardımcı teknik açıklamaları ön planda tuttuğunu ortaya koyuyor.
Uygulama: Yeni Messages API Özelliğini Kodlama
Yeni Messages API özelliği, geliştiricilerin bir konuşma sırasında sistem komut istemlerini (system prompt) anında güncellemesine olanak tanıyor. Bu, görev ortasında bütçe, izinler veya bağlam gibi parametreleri ayarlamak için son derece kullanışlı bir yenilik.
Aşağıdaki Python kodu örneğinde, bir sohbet sırasında araya nasıl yeni bir sistem talimatı eklendiğini görebilirsiniz:
import anthropic
# İstemciyi başlatıyoruz
client = anthropic.Anthropic()
# Konuşma geçmişine yeni sistem talimatını doğrudan yerleştiriyoruz
response = client.messages.create(
model="claude-opus-4-8",
max_tokens=1024,
messages=[
{"role": "user", "content": "Sana bir soru soracağım ama önce kuralları hatırla."},
{"role": "system", "content": "Bundan sonra vereceğin tüm yanıtlar sadece Türkçe ve olabildiğince kısa olmalıdır."},
{"role": "user", "content": "Yapay zekanın geleceği hakkında ne düşünüyorsun?"}
]
)
print(response.content[0].text)
Claude Opus 4.8 Fiyatlandırması
Modelin standart girdi/çıktı fiyatları korunurken, hızlı mod seçeneği çok daha avantajlı hale getirildi:
| Kullanım Türü | Girdi (Input) Ücreti (1 Milyon Jeton) | Çıktı (Output) Ücreti (1 Milyon Jeton) | Özellikler |
|---|---|---|---|
| Standart Kullanım | $5.00 | $25.00 | Varsayılan yüksek çaba ayarı ile dengeli performans |
| Hızlı Mod (Fast Mode) | $10.00 | $50.00 | 2.5 kat daha hızlı çalışma ve eski hızlı moda göre 3 kat daha ucuz |
Sonuç
Claude Opus 4.8; dürüst yapısı, dinamik iş akışı yetenekleri ve bütçe dostu hızlı modu ile yapay zeka destekli yazılım geliştirme süreçlerini tamamen değiştirmeye aday görünüyor. Hem kod kalitesindeki doğruluk oranının artması hem de geliştiricilere sunulan yeni API esnekliği, Anthropic’in bu yarışta çıtayı ne kadar yukarı taşıdığını kanıtlıyor.
Siz Claude Opus 4.8’in yeni dürüstlük ve kıyaslama test sonuçlarını nasıl buldunuz? Projelerinizde bu yenilikleri kullanmayı düşünüyor musunuz? Yorumlarda buluşalım ve deneyimlerinizi bizimle paylaşın!