
Herkese merhaba! 😁
Bugün çok heyecan verici bir konuya dalıyoruz. Google DeepMind, açık kaynak yapay zeka dünyasında adeta bir bomba patlattı: Gemma 4 modelleri resmen yayınlandı! 🚀
Hani diyorsunuz ya “açık kaynak modeller güzel ama kapalı kaynak modellerin yanına bile yaklaşamıyor”… Gemma 4 ile bu söylemi tekrar gözden geçirmeniz gerekecek. Çünkü bu model ailesi, parametre başına zeka konusunda şimdiye kadar gördüğümüz en etkileyici sonuçları sunuyor.
Üstelik tam bir Apache 2.0 lisansıyla geliyor. Yani tamamen açık kaynak ve ticari kullanıma açık. 🎉
Gemma 4 Nedir? 🤔
Gemma 4, Google DeepMind’ın Gemini 3 araştırma ve teknolojisi üzerine inşa ettiği en akıllı açık kaynak model ailesi. Basit sohbet botlarının çok ötesinde: karmaşık mantık yürütme, agentic workflow’lar (modelin kendi başına araç kullanarak görevler tamamlaması), kod üretimi ve multimodal anlama (metin, görüntü, ses gibi farklı veri tiplerini birlikte işleme) konularında ciddi yeteneklere sahip.
Gemma serisi lansmanından bu yana geliştiriciler modelleri 400 milyondan fazla kez indirdi ve 100.000’den fazla varyant oluşturarak devasa bir “Gemmaverse” ekosistemi kurdu. Gemma 4, bu topluluğun ihtiyaçlarına verilen bir cevap niteliğinde.
Model Boyutları ve Mimariler 📐
Gemma 4, dört farklı boyutta geliyor. Her biri farklı donanım ve kullanım senaryoları için optimize edilmiş:
| Model | Parametre | Context Window | Desteklenen Girdiler |
|---|---|---|---|
| Gemma 4 E2B | 2.3B efektif (5.1B toplam) | 128K | Metin, Görüntü, Ses |
| Gemma 4 E4B | 4.5B efektif (8B toplam) | 128K | Metin, Görüntü, Ses |
| Gemma 4 26B A4B (MoE) | 25.2B toplam / 3.8B aktif | 256K | Metin, Görüntü |
| Gemma 4 31B (Dense) | 30.7B | 256K | Metin, Görüntü |
E2B ve E4B: On-Device Modeller
İsimlerdeki “E” harfi “effective” anlamına geliyor. Bu modeller Per-Layer Embeddings (PLE) teknolojisi sayesinde parametre verimliliğini maksimize ediyor. Toplam parametre sayısı daha yüksek olsa da, inference (çıkarım) sırasında aktif olan parametre sayısı çok daha düşük.
Bu sayede telefon, Raspberry Pi, NVIDIA Jetson Nano gibi edge cihazlarda internete bile ihtiyaç duymadan, neredeyse sıfır gecikmeyle çalışabiliyorlar. 📱
Bu küçük modellerin bir avantajı da büyük modellerin aksine ses girişini desteklemeleri. Konuşma tanıma (ASR) ve konuşma çevirisi yapabiliyorlar.
26B MoE ve 31B Dense: Masaüstü ve Sunucu Modelleri
Büyük modeller araştırmacılar ve geliştiriciler için tasarlanmış:
26B A4B (MoE): Toplam 26 milyar parametre içinden inference sırasında sadece 3.8 milyarı aktif oluyor. Model içinde 128 adet expert (uzman ağ) var ve her çıkarımda bunların 8’i seçilerek kullanılıyor. Sonuç olarak 4B’lik bir modelin hızında çalışırken 26B’lik modelin kalitesini sunuyor.
31B Dense: Tüm parametrelerin aktif olduğu, maksimum kalite odaklı model. Fine-tuning için güçlü bir temel oluşturuyor. Quantize edilmiş versiyonları consumer GPU’larda bile çalışabiliyor.
Temel Yetenekler 🚀
Gemma 4’ün sunduğu yeteneklere bir göz atalım 👇🏻
Gelişmiş Reasoning ve Thinking Mode
Tüm modellerde thinking mode bulunuyor. Model, cevap vermeden önce adım adım düşünüp planını oluşturabiliyor. Özellikle matematik ve mantık gerektiren görevlerde bu mod ciddi fark yaratıyor.
AIME 2026 matematik benchmark’ında sonuçlar kendini gösteriyor:
- Gemma 4 31B: %89.2 ✅
- Gemma 4 26B MoE: %88.3 ✅
- Gemma 3 27B: %20.8 😬
Bir önceki nesle göre 4 kattan fazla iyileşme var!
Agentic Workflow’lar ve Function Calling
Gemma 4, native function calling ve structured JSON çıktısı desteğiyle geliyor. Modeli otonom bir ajan olarak çalıştırabilir, farklı araçlar ve API’lerle etkileşime sokabilirsiniz.
Somut bir örnek: Gemma 4’e Bangkok’taki bir tapınağın fotoğrafını gösterip “buradaki şehrin hava durumunu kontrol et” dediğinizde, model önce görüntüdeki lokasyonu analiz ediyor, sonra otomatik olarak get_weather(city="Bangkok") çağrısını oluşturuyor. Multimodal function calling bu kadar doğal çalışıyor. ✨
Multimodal Yetenekler
Gemma 4 sadece metin işleyen bir model değil:
- Görüntü: Nesne algılama, OCR, grafik yorumlama, doküman/PDF ayrıştırma, UI element tespiti, değişken aspect ratio (en-boy oranı) desteği
- Video: Kare kare video analizi (büyük modellerde sessiz, küçük modellerde sesli)
- Ses: ASR ve çok dilli konuşma çevirisi (sadece E2B ve E4B)
- Interleaved input: Aynı prompt’ta metin ve görselleri serbestçe karıştırabilirsiniz
Görsel token bütçesi de ayarlanabilir (70, 140, 280, 560, 1120). Detaylı analiz için yüksek bütçe, hız odaklı işler için düşük bütçe kullanabilirsiniz.
Kod Üretimi
Gemma 4 programlama benchmark’larında etkileyici sonuçlar elde etti:
- LiveCodeBench v6: %80.0 (31B)
- Codeforces ELO: 2150 (31B)
Bu skorlarla bilgisayarınızda çalışan güçlü bir lokal kod asistanı olarak kullanılabilecek seviyede.
Çoklu Dil Desteği
140’tan fazla dilde eğitilmiş. Sadece çeviri değil, kültürel bağlamı da anlayabiliyor. Çok dilli uygulamalar geliştirmek isteyen geliştiriciler için ciddi bir avantaj.
Uzun Context Window
- Edge modeller: 128K token
- Büyük modeller: 256K token
Tüm bir kod reposunu veya uzun dokümanları tek bir prompt’ta modele verebilirsiniz.
Mimari Yenilikler 🏗️
Gemma 4’ün performansının arkasındaki önemli mimari tercihlere göz atalım.
Per-Layer Embeddings (PLE)
Standart transformer’larda her token girişte tek bir embedding vektörü alır. PLE ise buna ek olarak her decoder katmanı için ayrı bir düşük boyutlu conditioning vektörü üretiyor. Bu vektör iki sinyalin birleşiminden oluşuyor: token kimliği (embedding lookup) ve bağlam bilgisi (ana embedding’in learned projection’ı).
Her katman sadece o anda ihtiyaç duyduğu token bilgisini alıyor. PLE boyutu ana hidden size’dan çok küçük olduğu için mütevazı parametre maliyetiyle katman başına ciddi uzmanlaşma sağlıyor.
Shared KV Cache
Son num_kv_shared_layers katmanlar kendi key-value projeksiyonlarını hesaplamıyor. Bunun yerine, aynı attention tipinin (sliding veya full) son non-shared katmanından K ve V tensorlarını tekrar kullanıyorlar.
Kalitede minimum etki yaratırken uzun context üretimi ve on-device kullanım için hem bellek hem compute açısından ciddi tasarruf sağlıyor.
Hybrid Attention
Model, yerel sliding window attention ile global full-context attention katmanlarını dönüşümlü olarak kullanıyor. Küçük modellerde 512, büyük modellerde 1024 token’lık sliding window tercih edilmiş. Dual RoPE yapılandırması da (sliding katmanlar için standart RoPE, global katmanlar için proportional RoPE) uzun context desteğini güçlendiriyor.
Benchmark Sonuçları 📊
Gemma 4’ün rakamlarla performansı:
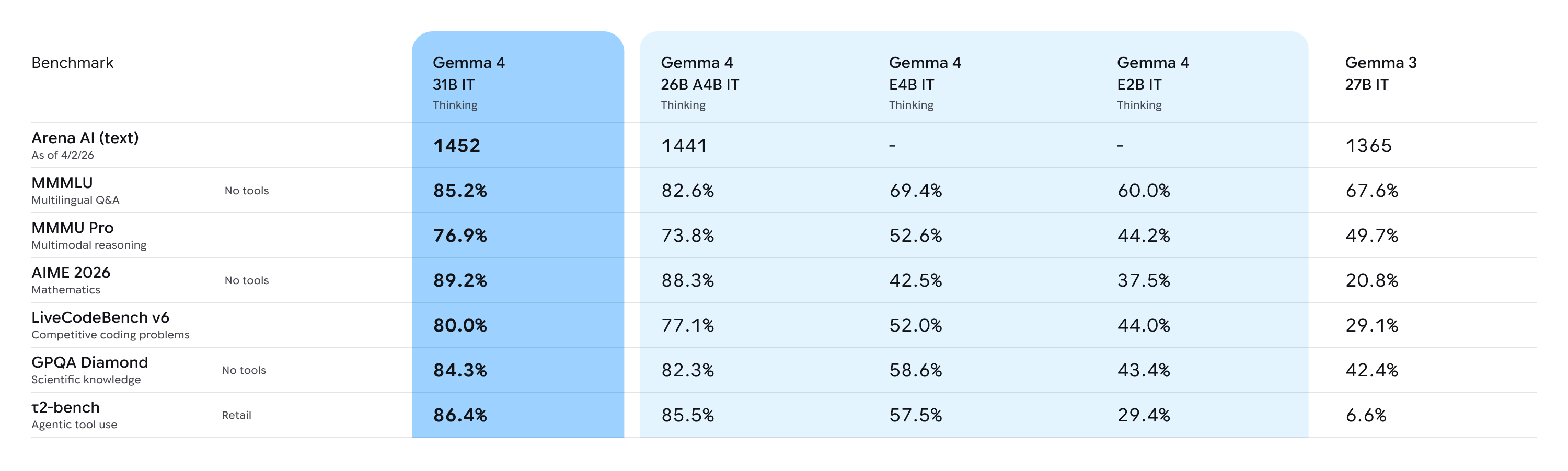
| Benchmark | Gemma 4 31B | Gemma 4 26B A4B | Gemma 4 E4B | Gemma 4 E2B | Gemma 3 27B |
|---|---|---|---|---|---|
| MMLU Pro (genel bilgi) | %85.2 | %82.6 | %69.4 | %60.0 | %67.6 |
| AIME 2026 (matematik) | %89.2 | %88.3 | %42.5 | %37.5 | %20.8 |
| LiveCodeBench v6 (kodlama) | %80.0 | %77.1 | %52.0 | %44.0 | %29.1 |
| GPQA Diamond (bilim) | %84.3 | %82.3 | %58.6 | %43.4 | %42.4 |
| MMMU Pro (multimodal) | %76.9 | %73.8 | %52.6 | %44.2 | %49.7 |
| MATH-Vision | %85.6 | %82.4 | %59.5 | %52.4 | %46.0 |
| Codeforces ELO | 2150 | 1718 | 940 | 633 | 110 |
| τ2-bench (agentic) | %76.9 | %68.2 | %42.2 | %24.5 | %16.2 |
Gemma 3’ten Gemma 4’e geçişte her alanda ciddi iyileşmeler var. Özellikle matematik (AIME: %20 → %89) ve kodlama (Codeforces: 110 → 2150) alanlarındaki sıçrama dikkat çekici.
Nasıl Kullanılır? 🛠️
Transformers ile Hızlı Başlangıç
En kolay yol, Hugging Face Transformers kütüphanesini kullanmak:
pip install -U transformers torch accelerate
import torch
from transformers import AutoProcessor, AutoModelForCausalLM
MODEL_ID = "google/gemma-4-E2B-it"
# Modeli yükle
processor = AutoProcessor.from_pretrained(MODEL_ID)
model = AutoModelForCausalLM.from_pretrained(
MODEL_ID,
dtype=torch.bfloat16,
device_map="auto"
)
# Prompt hazırla
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Türkiye'nin başkenti neresi?"},
]
# Girdiyi işle
text = processor.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False # Düşünme modunu etkinleştirmek için True yapın
)
inputs = processor(text=text, return_tensors="pt").to(model.device)
input_len = inputs["input_ids"].shape[-1]
# Çıktı üret
outputs = model.generate(**inputs, max_new_tokens=1024)
response = processor.decode(outputs[0][input_len:], skip_special_tokens=False)
# Yanıtı ayrıştır
processor.parse_response(response)
Pipeline ile Kullanım
Daha az kodla çalışmak isterseniz:
from transformers import pipeline
pipe = pipeline("any-to-any", model="google/gemma-4-e2b-it")
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "resim_url_veya_dosya_yolu"},
{"type": "text", "text": "Bu resimde ne görüyorsun?"},
],
}
]
output = pipe(messages, max_new_tokens=100, return_full_text=False)
print(output[0]["generated_text"])
llama.cpp ile Lokal Inference
Gemma 4’ü kendi bilgisayarınızda OpenAI-uyumlu bir API sunucusu olarak çalıştırabilirsiniz:
# macOS
brew install llama.cpp
# Windows
winget install llama.cpp
# Sunucuyu başlat
llama-server -hf ggml-org/gemma-4-26b-a4b-it-GGUF:Q4_K_M
Bu sunucuyu hermes, openclaw, pi, open code gibi lokal ajan araçlarıyla birlikte kullanabilirsiniz.
Ollama
En hızlı başlangıç yolu:
ollama run gemma4
MLX (Apple Silicon)
Apple Silicon kullanıcıları için mlx-vlm ile tam multimodal destek:
pip install -U mlx-vlm
mlx_vlm.generate \
--model google/gemma-4-E4B-it \
--image resim.jpg \
--prompt "Bu resmi detaylı olarak açıkla"
Fine-Tuning 🎛️
Gemma 4 fine-tuning için de güçlü bir temel sunuyor.
TRL ile Fine-Tuning
TRL kütüphanesi artık multimodal tool response’ları destekliyor. Yani eğitim sırasında model araçlardan sadece metin değil, görüntü de alabiliyor.
Güzel bir örnek: Gemma 4’ün CARLA simülatöründe sürüş öğrenmesi. Model kameradan yolu görüyor, karar veriyor ve sonuçtan öğreniyor. Eğitim sonrası yayalardan kaçınmak için şerit değiştirmeyi başarıyor! 🚗
pip install git+https://github.com/huggingface/trl.git
python examples/scripts/openenv/carla_vlm_gemma.py \
--env-urls https://sergiopaniego-carla-env.hf.space \
--model google/gemma-4-E2B-it
Unsloth Studio
Görsel arayüzle fine-tuning yapmak isteyenler için:
# macOS, Linux, WSL
curl -fsSL https://unsloth.ai/install.sh | sh
# Windows
irm https://unsloth.ai/install.ps1 | iex
# Başlat
unsloth studio -H 0.0.0.0 -p 8888
Vertex AI
Google Cloud üzerinde Vertex AI Serverless Training Jobs ile ölçeklenebilir fine-tuning yapmak da mümkün. Özel Docker container’lar ile CUDA destekli eğitim kurulumu sağlanabiliyor.
Apache 2.0 Lisansı ⚖️
Bu belki de en önemli detaylardan biri. Gemma 4 Apache 2.0 lisansı altında yayınlanıyor:
- ✅ Ticari kullanım serbestçe yapılabilir
- ✅ Modeli değiştirip kendi versiyonunuzu oluşturabilirsiniz
- ✅ Verileriniz, altyapınız ve modelleriniz üzerinde tam kontrol
- ✅ On-premise veya cloud, istediğiniz yerde deploy edebilirsiniz
Önceki bazı “açık” modeller kısıtlayıcı lisanslarla geliyordu. Gemma 4’ün Apache 2.0 ile gelmesi gerçek anlamda özgür bir model olduğunu gösteriyor.
Güvenlik ve Etik 🛡️
Gemma 4, Google’ın proprietary (kapalı kaynak) modelleriyle aynı güvenlik protokollerinden geçiyor:
- CSAM filtreleme (çocuk istismarı içeriklerine karşı) uygulanmış
- Kişisel ve hassas veri filtreleme yapılmış
- İçerik kalitesi ve güvenliği açısından Google’ın AI politikalarına uygun şekilde filtrelenmiş
Güvenlik testlerinde önceki Gemma modellerine kıyasla tüm kategorilerde önemli iyileşmeler gözlemlenmiş.
Nereden İndirilir? 📥
Gemma 4 modellerini şu platformlardan indirebilirsiniz:
- 🤗 Hugging Face
- 📦 Kaggle
- 🦙 Ollama
Hemen denemek isterseniz Google AI Studio üzerinden 31B ve 26B modellerini tarayıcınızdan test edebilir, Google AI Edge Gallery üzerinden de E4B ve E2B modellerini deneyebilirsiniz.
Sonuç
Gemma 4, açık kaynak yapay zeka alanında ciddi bir adım. Parametre başına rekor kıran performansı, Apache 2.0 lisansı, edge cihazlardan sunuculara kadar geniş donanım desteği ve multimodal yetenekleriyle geliştiriciler için çok güçlü bir araç.
Eğer daha önce açık kaynak LLM’leri nasıl kullanacağınızı merak ediyorsanız veya kendi lokal AI sunucunuzu kurmak istiyorsanız, Gemma 4 değerlendirmeniz gereken bir model ailesi.
Siz ne düşünüyorsunuz? Gemma 4’ü denemeyi planlıyor musunuz? Hangi boyut sizin kullanım senaryonuza uyar? Yorumlarda tartışalım! 👇🏻
İyi kodlamalar! 😊