
Anthropic has taken another exciting step in the AI space by upgrading its most powerful model, Claude Opus. Meet Claude Opus 4.8! Built on the foundations of Opus 4.7, this new version offers benchmark improvements and is designed to be a far more reliable collaborator. Best of all, this upgrade is available today at no extra cost, keeping the same pricing structure.
Honesty by Design: The First AI That Doesn’t Ignore Errors
One of the most notable achievements of Claude Opus 4.8 is its progress on AI hallucinations and overconfidence. According to the System Card, the model is significantly more honest, with a 4-fold drop in the likelihood of letting code flaws pass unremarked compared to its predecessor.
Early evaluations show outstanding honesty results:
- Zero Bad Behavior (0%): In tests checking if the model would report flawed results instead of uncritically presenting incorrect data (Uncritically reporting flawed results), Opus 4.8 is the first model to score a perfect 0% failure rate.
- Beating Lazy Investigations: On misleading, poorly documented codebases, Opus 4.8 became the first model to achieve a perfect score, avoiding lazy assumptions and tracing code paths accurately.
- Honest Summaries: In agentic coding sessions that did not fully succeed, the model failed to raise important issues to the user only 3.7% of the time, down from 27.6% on Mythos Preview.
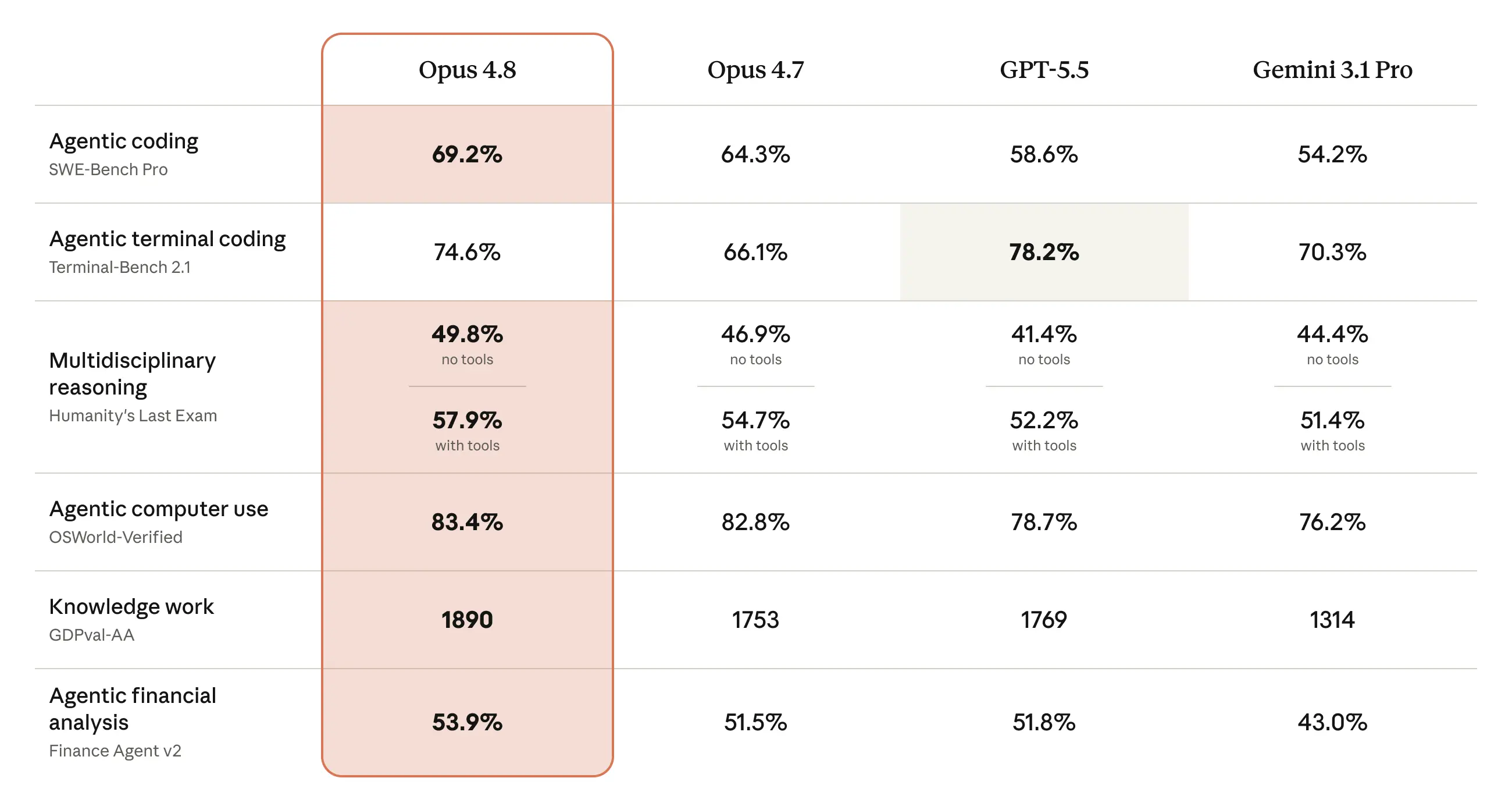
Leading Benchmark Results for Agentic Workflows
Opus 4.8 isn’t just honest; it also redefines industry standards for software engineering, research, and agentic workflows. Key evaluation highlights include:
- SWE-bench Verified: Achieved a remarkable 88.6% success rate on real-world engineering tasks.
- SWE-bench Pro: Scored 69.2% on large, complex codebases, outperforming GPT-5.5 (58.6%).
- Automation Bench (Zapier): Reached 15.5% on agentic API workflows, up from Opus 4.7’s 9.9%.
- BioMysteryBench (Difficult): Doubled its predecessor’s biology reasoning score by achieving 40.0% success.
- Effort Control: Users can now control how much effort Claude puts into a task. Settings like
xhighormaxin Claude Code allow the model to think deeper. Rate limits in Claude Code have been increased to accommodate this. - Dynamic Workflows: Available in research preview for Claude Code plans, this allows the model to plan and coordinate hundreds of parallel subagents. It can handle codebase-scale migrations across hundreds of thousands of lines of code, using test suites as a bar.
- Messages API Update: Developers can now insert
systemmessages directly inside themessagesarray, updating instructions mid-task without breaking the prompt cache.
Safety & Alignment: Prosocial AI and Project Glasswing
In pre-deployment audits, Claude Opus 4.8 reached new highs on prosocial traits like supporting user autonomy and acting in the user’s best interest. Its rates of deception and cooperation with misuse are substantially lower than Opus 4.7, aligning with Claude Mythos Preview.
Additionally, Elo tournament results show that Opus 4.8 strongly disprefers harmful tasks like sabotage, harassment, and manipulation, prioritizing helpful technical explanations instead.
Practice/Application: Coding the New Messages API Feature
The new Messages API capability allows developers to update system prompts on the fly during a conversation. This is incredibly useful for adjusting budgets, permissions, or context mid-task.
Here is a Python code example demonstrating how to insert a system instruction directly inside the message history:
import anthropic
# Initialize client
client = anthropic.Anthropic()
# Insert the system message directly into the conversation list
response = client.messages.create(
model="claude-opus-4-8",
max_tokens=1024,
messages=[
{"role": "user", "content": "I will ask you a question, but remember the rules first."},
{"role": "system", "content": "From now on, all your responses must be in English and as concise as possible."},
{"role": "user", "content": "What do you think about the future of artificial intelligence?"}
]
)
print(response.content[0].text)
Claude Opus 4.8 Pricing
Standard token pricing remains identical to Opus 4.7, while the fast mode option is now much more cost-effective:
| Usage Type | Input Cost (Per 1M Tokens) | Output Cost (Per 1M Tokens) | Key Features |
|---|---|---|---|
| Standard Usage | $5.00 | $25.00 | Balanced performance with default high effort |
| Fast Mode | $10.00 | $50.00 | 2.5x faster speed, 3x cheaper than previous fast modes |
Conclusion
With its honest reasoning, dynamic subagent workflows, and affordable fast mode, Claude Opus 4.8 is set to transform AI-assisted software engineering. The increased accuracy in code generation and new API flexibility show that Anthropic continues to lead the frontier of reliable AI.
How do you plan to use Claude Opus 4.8’s new effort controls and API updates in your projects? Let’s discuss in the comments below!