

Important Note: Meta has announced a new chapter in the history of artificial intelligence today. The Llama 4 series is surpassing its competitors with its multimodal AI capabilities and revolutionary mixture-of-experts architecture. In initial tests, it manages to outperform leading models like GPT-4o and Gemini 2.0!
Llama 4: A Revolution in Multimodal AI 🚀
Meta has officially announced Llama 4 models, which will open a new chapter in the world of artificial intelligence. This new model family stands out especially with its multimodal capabilities and mixture-of-experts (MoE) architecture. Continuing Meta’s open-weight model approach, Llama 4 represents an important step in the AI ecosystem with both its performance and accessibility.
These new generation Llama models bring effective solutions to three major problems in artificial intelligence:
- Efficiency Problem: Superior performance using fewer resources with MoE architecture
- Multimodality Problem: Natural integration of text and visuals
- Context Window Problem: Unlimited context capability with 10 million tokens
Knowledge Cutoff Date: August 2024
Officially Supported Languages: Arabic, English, French, German, Hindi, Indonesian, Italian, Portuguese, Spanish, Tagalog, Thai, and Vietnamese
Llama 4 Model Family: The Three Pillars of Next Generation AI
Meta presents three different variants as the first models of the Llama 4 series:
Llama 4 Scout: Multimodal Intelligence Running on a Single GPU
- Active Parameters: 17 billion
- Number of Experts: 16
- Total Parameters: 109 billion
- Context Window: 10 million tokens (industry leader)
- Training Token Count: ~40 trillion
- Key Feature: Ability to run with Int4 quantization on a single NVIDIA H100 GPU
Remarkable Feature: Llama 4 Scout’s 10 million token context window is approximately 80 times larger than GPT-4’s 128 thousand token limit! This means being able to process an entire book, technical documentation, or hours of conversation history in a single pass.
Performance Comparison: Llama 4 Scout outperforms similar-sized models including Gemma 3, Gemini 2.0 Flash-Lite, and Mistral 3.1 across a broad range of widely reported benchmarks.
Llama 4 Maverick: Best in Class
- Active Parameters: 17 billion
- Number of Experts: 128
- Total Parameters: 400 billion
- Context Window: 1 million tokens
- Training Token Count: ~22 trillion
- Key Feature: Top-tier performance/cost ratio
Comparison: Llama 4 Maverick surpasses GPT-4o and Gemini 2.0 Flash while showing performance similar to DeepSeek v3 with half the parameter count. Its experimental chat version, which scored 1417 ELO on LMArena, achieves top-tier success in its class.
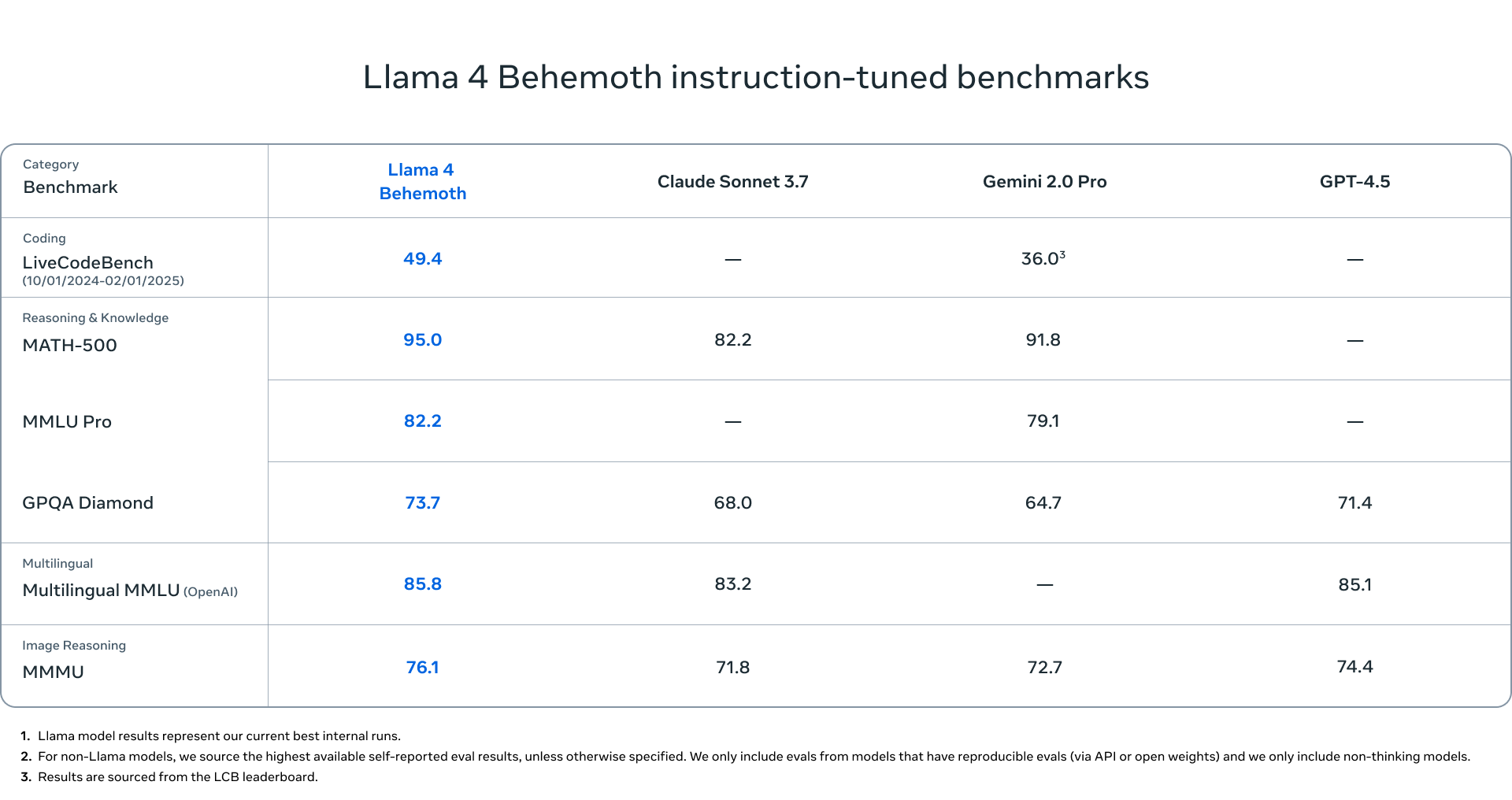
Llama 4 Behemoth: Meta’s Massive Teacher
- Active Parameters: 288 billion
- Number of Experts: 16
- Total Parameters: Approximately 2 trillion
- Key Feature: Superior performance in STEM domains compared to GPT-4.5 and Claude Sonnet 3.7
Note: Meta is not currently releasing this massive model with approximately 2 trillion parameters as its training is still ongoing, but mentions that it serves as a “teacher” to its smaller siblings during the training process.
Architecture and Technical Innovations
Mixture-of-Experts (MoE) Architecture: Intelligent Division of Labor
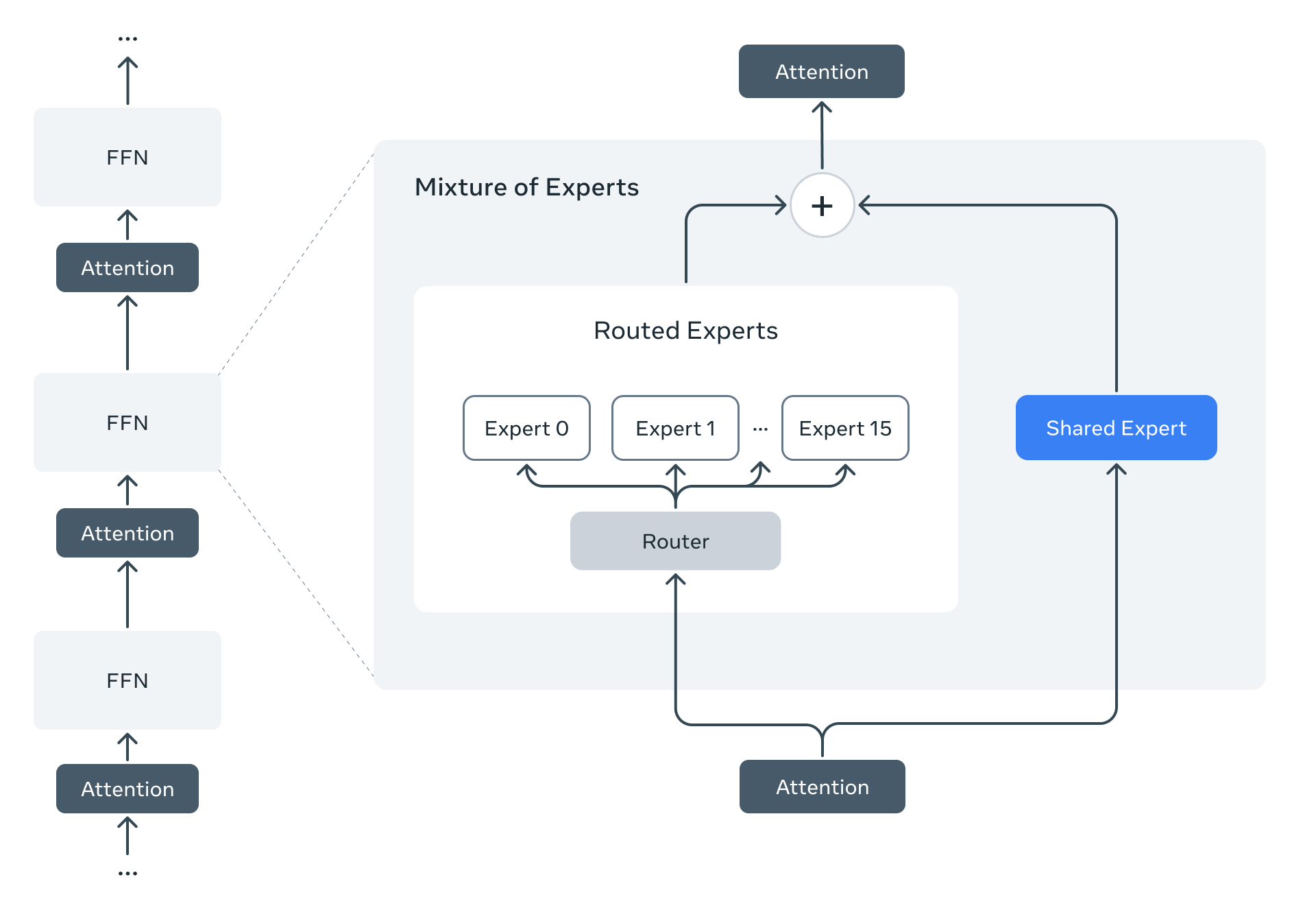
Llama 4 models stand out as the first models where Meta uses the MoE architecture. This architecture provides incredible efficiency by activating only a portion of the total parameters per token.
For example, in the Llama 4 Maverick model:
- 17 billion active parameters
- 400 billion total parameters
- MoE layers contain 128 routed experts + 1 shared expert
- Each token activates the shared expert AND only one from the 128 experts
- This reduces computational cost by up to 95%!
Native Multimodality: Visual and Text Integration
Llama 4 models provide natural integration with an “early fusion” technique, unlike other models that process text and images separately:
- Previous Models: Image → Image Encoder → Text Translation → LLM → Response
- Llama 4: Image + Text → Single Model Processing → Response
This approach enables deeper and more natural understanding of visuals and allows pre-training the model with large amounts of unlabeled text, image, and video data.
iRoPE: The Secret Behind 10 Million Token Context
The technical innovation enabling Llama 4 Scout’s revolutionary 10 million token context window is the “iRoPE” architecture:
- i: “interleaved” attention layers
- RoPE: Rotary Position Embedding
This architecture makes theoretically infinite context possible by using interleaved attention layers without positional embeddings and applying attention temperature scaling during inference time.
Performance and Comparisons: How It Surpasses Competitors 📊
Pre-trained Models Comparison
| Category | Benchmark | Metric | Llama 3.1 70B | Llama 3.1 405B | Llama 4 Scout | Llama 4 Maverick |
|---|---|---|---|---|---|---|
| Reasoning & Knowledge | MMLU | accuracy | 79.3 | 85.2 | 79.6 | 85.5 |
| MMLU-Pro | accuracy | 53.8 | 61.6 | 58.2 | 62.9 | |
| MATH | pass@1 | 41.6 | 53.5 | 50.3 | 61.2 | |
| Coding | MBPP | pass@1 | 66.4 | 74.4 | 67.8 | 77.6 |
| Multilingual | TydiQA | average/f1 | 29.9 | 34.3 | 31.5 | 31.7 |
| Image | ChartQA | accuracy | No multimodal support | 83.4 | 85.3 | |
| DocVQA | anls | 89.4 | 91.6 | |||
Noteworthy Result: Llama 4 Maverick performs 14.4% better than the Llama 3.1 405B model in mathematics (MATH benchmark) - using less than half the active parameters!
Instruction-tuned Models Comparison
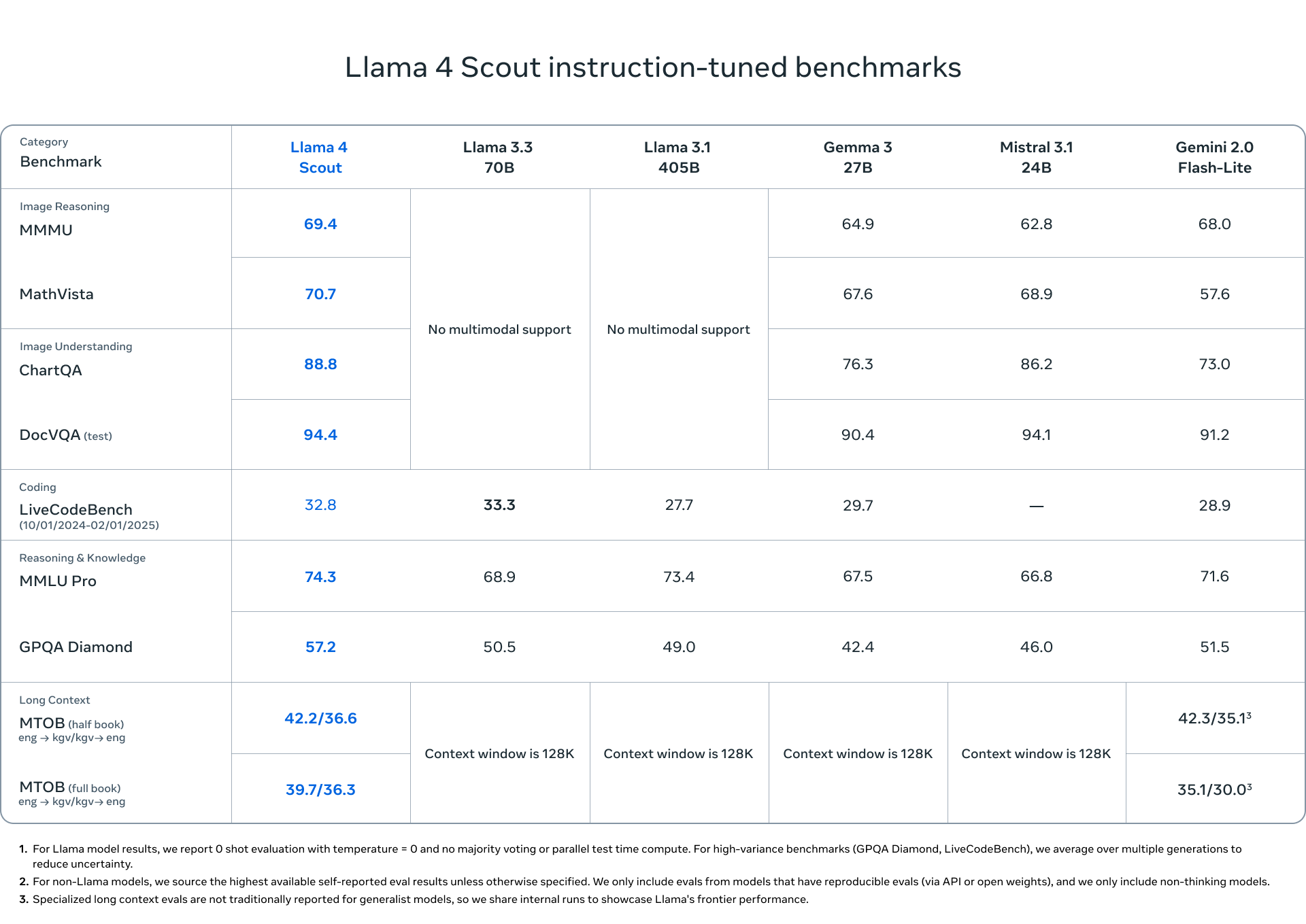
| Category | Benchmark | Metric | Llama 3.3 70B | Llama 3.1 405B | Llama 4 Scout | Llama 4 Maverick |
|---|---|---|---|---|---|---|
| Visual Reasoning | MMMU | accuracy | No multimodal support | 69.4 | 73.4 | |
| MMMU Pro | accuracy | 52.2 | 59.6 | |||
| MathVista | accuracy | 70.7 | 73.7 | |||
| Visual Understanding | ChartQA | accuracy | 88.8 | 90.0 | ||
| DocVQA (test) | anls | 94.4 | 94.4 | |||
| Coding | LiveCodeBench (10/01/2024-02/01/2025) |
pass@1 | 33.3 | 27.7 | 32.8 | 43.4 |
| Reasoning & Knowledge | MMLU Pro | accuracy | 68.9 | 73.4 | 74.3 | 80.5 |
| GPQA Diamond | accuracy | 50.5 | 49.0 | 57.2 | 69.8 | |
| Multilingual | MGSM | average/em | 91.1 | 91.6 | 90.6 | 92.3 |
| Long Context | MTOB (half book) eng->kgv/kgv->eng |
chrF | Context window is 128K | 42.2/36.6 | 54.0/46.4 | |
| MTOB (full book) eng->kgv/kgv->eng |
chrF | 39.7/36.3 | 50.8/46.7 | |||
Striking Result: Llama 4 Maverick performs 38.2% better than the Llama 3.3 70B model in the extremely difficult GPQA Diamond benchmark and makes a major leap in solving advanced physics and mathematics questions from literature!
Real World Performance: What Does Llama 4 Change? 📱
What do Llama 4’s innovations mean in practice? Here are some notable use cases:
1. Visual Understanding and Explanation
Llama 4 breaks new ground in understanding and explaining complex visuals:
- Medical Images: Ability to detect anomalies in MRI, X-ray, and other medical images
- Graphs and Tables: Ability to analyze and summarize complex graphs in business reports
- Technical Diagrams: Ability to understand architectural drawings, circuit diagrams, and technical drawings
2. Ultra-Long Context Capabilities
With a 10 million token context window:
- Understanding Entire Books: Ability to process and discuss a novel or technical book as a whole
- Code Base Analysis: Ability to comprehensively analyze projects containing millions of lines of code
- Personalized Learning: Ability to provide personalized education by remembering a student’s entire learning history
Concrete Example: Llama 4 Scout can read and analyze the 625-page “War and Peace” novel in a single pass and simultaneously compare the development of characters at the beginning and end of the novel - without experiencing any context loss!
Training Process and Technical Details 🛠️
MetaP: Revolution in Hyper-parameter Optimization
Meta reliably adjusts critical model hyper-parameters with its “MetaP” technique developed for Llama 4 models. This technique:
- Automatically determines learning rates per layer
- Optimizes initialization scales
- Produces transferable results for different batch sizes, model widths, and depths
Training Data Mixture
Data mixture used for Llama 4 models:
- Total Tokens: 30+ trillion (2x that of Llama 3)
- Language Coverage: 200+ languages (1 billion+ tokens in more than 100 languages)
- Data Types: Text, images, video frames
- Data Sources: Public data, licensed content, public posts from Instagram and Facebook
- Training Compute: Llama 4 Scout utilized 5.0M GPU hours, while Maverick used 2.38M GPU hours on H100-80GB hardware
- Environmental Impact: Meta maintains net zero greenhouse gas emissions, resulting in 0 market-based emissions despite the intensive training
Training Process and Model Distillation
Meta uses a special distillation strategy to enhance the performance of smaller models:
- Behemoth Training: First, the 2 trillion parameter Behemoth model is trained
- Codistillation: The Behemoth model is used as a “teacher” to transfer knowledge to Scout and Maverick models
- Dynamic Weighting: Dynamic weighting of soft and hard targets during training
Interesting Note: Meta’s researchers had to eliminate 95% of the SFT data for Behemoth model training. For smaller models, this ratio was 50%. This shows that larger models are “more selective”!
Multi-turn Reinforcement Learning
Meta uses a multi-turn reinforcement learning (RL) strategy in model training by:
- Difficulty Detection: Identifying difficult prompts with pass@k analysis
- Dynamic Filtering: Dynamically filtering out prompts with zero advantage value during training
- Mixed Capability Groups: Combining prompts from different capabilities in the same training batch
These strategies provide significant performance improvements especially in mathematics, reasoning, and coding abilities.
Safety and Protection Measures: Powerful and Responsible AI 🛡️
Meta took comprehensive safety measures while developing Llama 4 models:
Model-Level Improvements
- Red Teaming: Cybersecurity and adversarial machine learning experts conducted systematic tests
- GOAT (Generative Offensive Agent Testing): A new security testing approach that simulates multi-turn interactions
- Balanced Political Stance: In Llama 4, the rate of response rejection on political and social issues was reduced from 7% to below 2%
Open Source Security Tools
Meta also provides open source security tools that can be used with Llama 4:
| Tool | Function | Usage Area |
|---|---|---|
| Llama Guard | Controls input/output security | Harmful content detection |
| Prompt Guard | Malicious prompt detection | Prompt injection protection |
| CyberSecEval | Cybersecurity risk analysis | AI security assessment |
Security Test Focus Areas
Meta specifically focused on three critical risk areas:
-
CBRNE (Chemical, Biological, Radiological, Nuclear, and Explosive Materials)
- Expert tests evaluating the model’s potential for weaponization
- Resilience tests against various attack vectors
-
Child Safety
- Multimodal and multilingual child safety assessments
- Content filtering and data security strategies
-
Cyber Attack Capability
- Evaluation of cyber attack automation capabilities
- Testing capabilities to detect and exploit security vulnerabilities
Conclusion: According to Meta’s comprehensive security assessments, Llama 4 models do not increase risks that could lead to catastrophic cyber outcomes.
Llama 4’s Application Areas: Unlimited Potential 🌐
Usage Scenarios by Sector
Software Development Revolution
Llama 4 Maverick’s success in coding with a 43.4% pass@1 rate on LiveCodeBench has the potential to transform software development processes:
- Full Project Analysis: Ability to work on the entire codebase with a 10M token context window
- Code Optimization: Making existing code more efficient
- Architectural Design: Proposing system architecture and assisting in design
- Debugging: Identifying sources of complex errors
Groundbreaking Capabilities in Health and Medicine
With its multimodal capabilities, Llama 4 in the healthcare sector:
- Medical Image Analysis: Detecting anomalies in MRI, X-ray, and other medical images
- Patient Record Analysis: Providing diagnosis and treatment recommendations by analyzing long patient histories
- Medical Literature Review: Recommending evidence-based medical practices by scanning thousands of research papers
Visual Processing Capability: Llama 4 models were thoroughly tested on up to 5 input images with excellent results, making them reliable for multi-image analysis tasks.
Personalized Experience in Education
Thanks to the 10M token length context window:
- Personalized Learning: Providing custom content by remembering a student’s entire learning history
- Lesson Plan Creation: Customized lesson plans based on the student’s strengths and weaknesses
- Multimodal Teaching: Ability to explain complex topics with texts, visual explanations, and graphics
Data Analytics in Business
Multimodal capabilities and long context in the business world:
- Financial Analysis: Holistic analysis of long-term financial reports, graphs, and tables
- Market Research: Determining market trends by analyzing large amounts of text and visual data
- Document Understanding: Analyzing complex contracts, policies, and reports
Looking to the Future: The Rise of the Llama Ecosystem 🔮
Meta continues to expand the AI ecosystem with the Llama 4 series:
- LlamaCon Event: More details about Llama 4 will be announced on April 29
- Open Ecosystem: Meta continues to support more innovation with its open source approach
- Accessibility: Access to Llama 4 via Meta AI through WhatsApp, Messenger, Instagram Direct
Final Word: Llama 4 initiates a new era in the field of artificial intelligence with its multimodal capabilities, long context window, and efficient MoE architecture. When combined with Meta’s open ecosystem approach, these developments herald a completely different landscape in the field of artificial intelligence in the coming years.
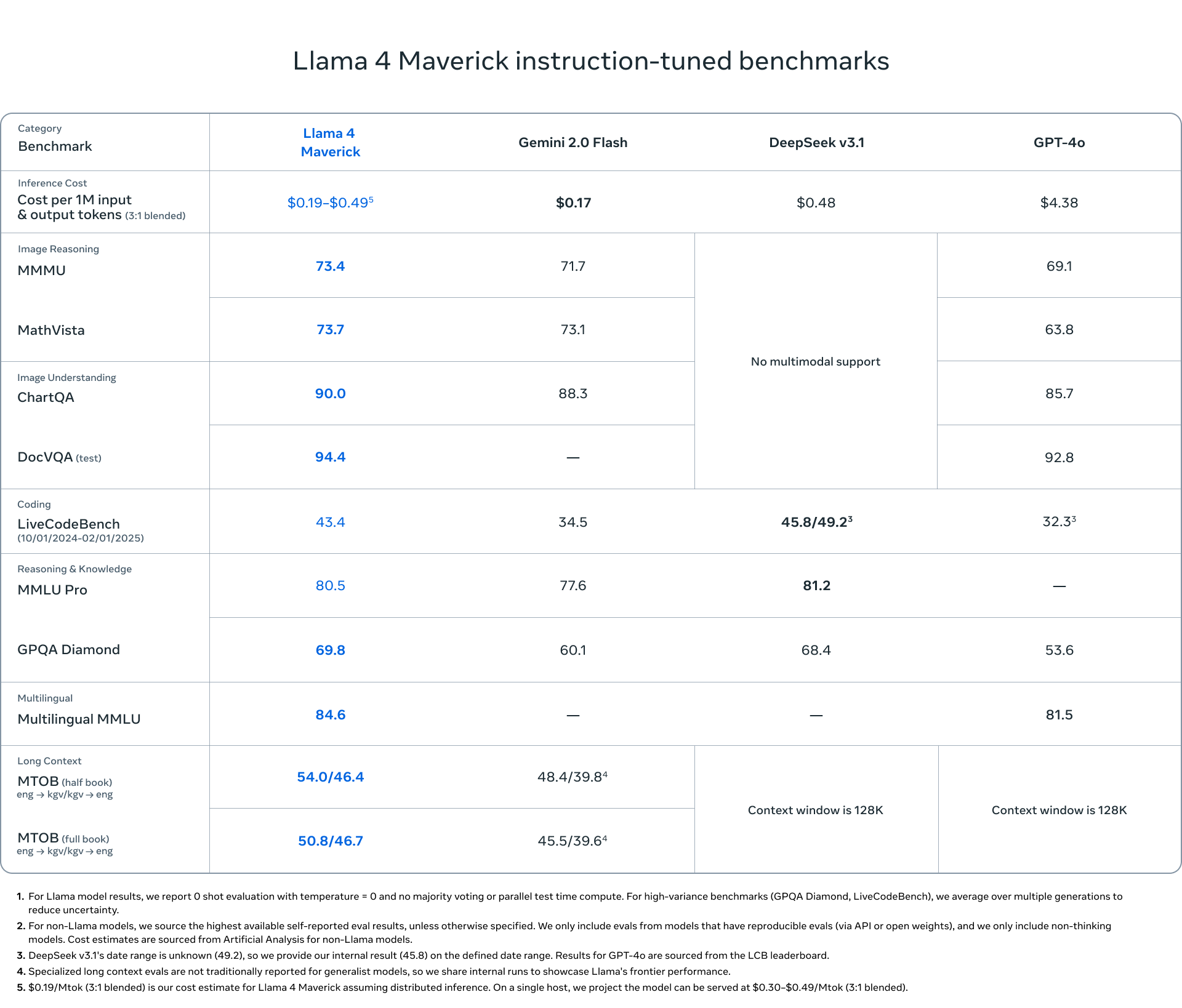
API Pricing and Cost Comparison 💰
Meta’s aggressive pricing strategy makes Llama 4 models not only technically impressive but also economically attractive compared to competitors:
Llama 4 Maverick: Premium Performance at Fraction of the Cost
| Model | Cost per 1M tokens (3:1 input/output blend) | MMMU | GPQA Diamond | LiveCodeBench |
|---|---|---|---|---|
| Llama 4 Maverick | $0.19-$0.49 | 73.4 | 69.8 | 43.4 |
| GPT-4o | $4.38 (23x more expensive) | 69.1 | 53.6 | 32.3 |
| Gemini 2.0 Flash | $0.17 | 71.7 | 60.1 | 34.5 |
| DeepSeek v3.1 | $0.48 | No multimodal support | 68.4 | 45.8/49.2 |
Price-Performance Analysis: Llama 4 Maverick delivers superior performance at just ~1/23 the cost of GPT-4o, making it an extremely cost-effective option for enterprise deployments. When running distributed inference, the cost can be as low as $0.19 per million tokens.
Llama 4 Scout: Single GPU Efficiency
While exact pricing hasn’t been disclosed for Scout’s API, its ability to run on a single H100 GPU with Int4 quantization makes it exceptionally resource-efficient compared to similar models in its class. Organizations can deploy it on-premises with significantly lower hardware requirements than competing models.
Enterprise Cost Optimization: For large-scale deployments processing billions of tokens monthly, switching from GPT-4o to Llama 4 Maverick could result in cost savings of over 95%, potentially translating to millions of dollars annually for high-volume users.
Try It Now! 🚀
- Llama 4 Scout and Maverick models are now available to download from llama.com and Hugging Face
- You can experience Llama 4 immediately through Meta AI on WhatsApp, Messenger, and the web
- Developers also have access to security tools like Llama Guard, Prompt Guard, and CyberSecEval
Meta officially announced the Llama 4 models and features mentioned in this article on April 5, 2025. Model features and performance may change in the future. This blog may be updated with new developments or error corrections.