

Hello friends! Today I’ll be talking about OpenAI’s newly released next-generation audio models. These models are taking the interaction between AI and voice to a completely new level!
What’s Coming?
OpenAI has been working on text-based agents for the past few months - like Operator, Deep Research, and Computer-Using Agents. But to create a true revolution, people need to be able to interact with AI in a more natural and intuitive way. That’s why they’ve made a huge leap in audio technologies.
The newly released models are:
- GPT-4o-transcribe and GPT-4o-mini-transcribe: Advanced models that convert speech to text
- GPT-4o-mini-tts: A new model that converts text to speech and even lets you adjust speaking style
Revolution in Speech Recognition (Speech-to-Text) Models
The new gpt-4o-transcribe and its smaller sibling gpt-4o-mini-transcribe offer much better performance than the older Whisper models. These models:
- Better understand speech in different accents
- Provide high success rates even in noisy environments
- Adapt better to varying speech speeds
- Show significant improvement in Word Error Rate (WER) scores
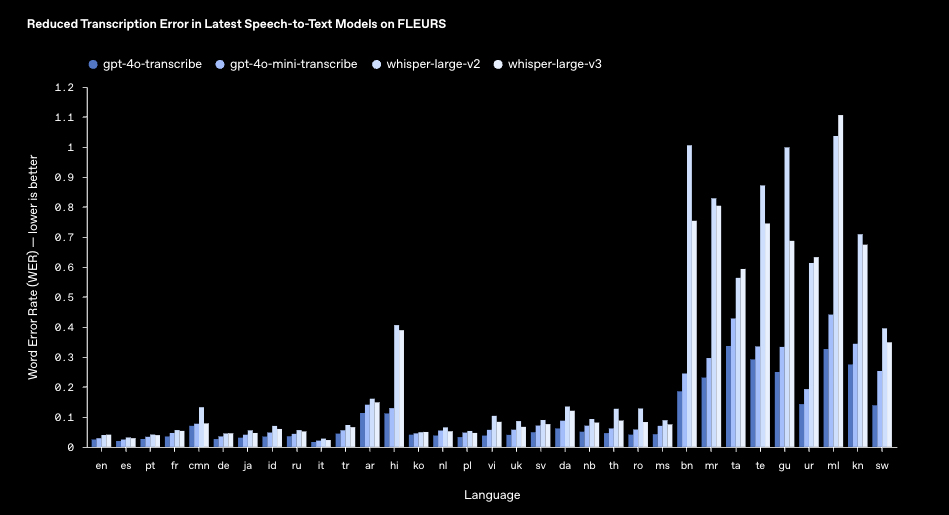
Detailed Performance Comparisons
According to FLEURS (Few-shot Learning Evaluation of Universal Representations of Speech) evaluations, OpenAI’s new models show superior performance in all languages. Here are WER (Word Error Rate) comparisons for some prominent languages - the lower, the better:
| Language | GPT-4o-transcribe | GPT-4o-mini-transcribe | Whisper-large-v3 |
|---|---|---|---|
| English | 0.035 | 0.037 | 0.045 |
| Spanish | 0.049 | 0.051 | 0.068 |
| Portuguese | 0.057 | 0.060 | 0.078 |
| French | 0.063 | 0.065 | 0.082 |
| Chinese | 0.120 | 0.125 | 0.152 |
| Turkish | 0.085 | 0.089 | 0.113 |
| Japanese | 0.097 | 0.102 | 0.138 |
| Russian | 0.078 | 0.082 | 0.104 |
Comparisons with other industry-leading models also show impressive results. GPT-4o-transcribe and GPT-4o-mini-transcribe models outperform competitors like Gemini-2.0-flash, Scribe-v1, and Nova-2/3.
Revolution in Text-to-Speech
GPT-4o-mini-tts is breaking new ground in text-to-speech conversion technology. For the first time, you can specify not just “what” a model should say, but “how” it should say it!
Voice Character Examples
The variety of voice characters prepared by OpenAI is very rich. Here are a few examples:
- Calm: A soft, balanced, and soothing tone
- Surfer: A relaxed, carefree, and energetic speaking style
- Professional: A clear, confident, and formal voice tone
- Medieval Knight: A ceremonial and elaborate speech pattern
- True Crime Enthusiast: A dramatic, mysterious, and tense narration
At OpenAI’s demo event, a model speaking in the style of a “mad scientist” made its debut, saying “The stars tremble before my genius! Energy fluctuating, unstable, perhaps dangerous…” delivering an impressive performance.
By providing these instructions, you can adjust the tone, speed, emotion, and character of the voice. You can try this feature yourself at openai.fm.
OpenAI.fm: An Interactive Platform to Experience Audio Models
OpenAI has released an interactive platform called openai.fm where everyone can experience their new audio models. This platform allows you to instantly try, gamify, and share text-to-speech transformation technology.
How to Use It?
OpenAI.fm has an extremely user-friendly interface. To use the platform:
- Go to openai.fm
- Choose one of the ready-made voice characters (Alloy, Echo, Fable, Onyx, Nova, Shimmer, etc.)
- Select one of the ready-made prompts or enter your own text
- Add custom instructions for speaking style (This part is GPT-4o-mini-tts’s most innovative feature!)
- Press “Generate” and listen to the created audio
Voice Styles and Instructions
On OpenAI.fm, you can completely control the speaking style along with the voice character. Here are some interesting instruction examples:
- Emotional states: “Speak very excited and a little nervous”, “Whisper in a calm and soothing tone”
- Character voices: “Speak heavy and authoritative like an old sage”, “Speak monotonous and mechanical like a robot”
- Business scenarios: “Be clear and energetic like a professional conference presenter”, “Speak softly and understandingly like an empathetic therapist”
- Creative narration: “Be an epic movie trailer narrator”, “Speak warm and intriguing as if reading a children’s book”
Yaroslav Nikulin (OpenAI engineer) said during the live demo event: “You can specify the tone, speed, emotion, and character you want. You can write a completely free-form request, and you can expect the model to understand it.”
Creative Projects and Competitions
OpenAI also organized a competition to celebrate this technology with the community. Users were asked to create the most creative audio experiences on the openai.fm platform and share them on Twitter. Winners received special production Teenage Engineering radios with the OpenAI logo.
Some creative examples created on the platform:
- An emergency announcement as a spaceship captain
- A documentary narration of a house cat in David Attenborough style
- A modern technology presentation in the style of a 1950s radio advertisement
- A yoga coach guidance in ASMR style
Exploring the Platform Code
You can also access the code of the OpenAI.fm platform. By clicking on “Show code,” you can access Python, JavaScript, or cURL examples and see how you can use them in your own applications:
from openai import OpenAI
client = OpenAI()
response = client.audio.speech.create(
model="gpt-4o-mini-tts",
voice="alloy",
instructions="Speak like an excited scientist, high energy and intriguing",
input="Today I made a groundbreaking discovery! Imagine, a particle that completely changes the structure of matter! This will redefine the limits of physics as we know it!"
)
response.stream_to_file("output.mp3")
Technical Innovations
There are serious technical innovations behind these models:
1. Pre-training with authentic audio data
The new audio models were built on the GPT-4o and GPT-4o-mini architectures and trained with specialized audio datasets. These audio-centric datasets contain trillions of audio tokens and enable the models to better grasp audio nuances. This targeted approach provides the ability to understand speech intricacies more deeply and deliver exceptional performance in audio-related tasks.
2. Advanced distillation methods
OpenAI optimized their distillation techniques to transfer knowledge from the largest audio models to smaller, more efficient models. Distillation datasets created using advanced self-play methodologies capture realistic conversation dynamics that mimic real user-assistant interactions. This allows smaller models to deliver excellent conversation quality and response speed.
3. Reinforcement learning paradigm
A reinforcement learning (RL)-heavy paradigm was integrated into speech recognition models. This approach maximizes transcription accuracy, reduces hallucinations, and makes models particularly competitive in complex speech recognition scenarios.
What Are Voice Agents?
The new audio models particularly strengthen the concept of “voice agents.” Voice agents are AI systems that understand users’ voice commands and respond with voice. There are two ways to create them:
1. Speech-to-Speech Method
A faster and more natural approach that directly understands audio input and provides a voice response. This method:
- Offers lower latency
- Provides more natural-feeling interactions
- Powers ChatGPT’s advanced voice mode
- Can be accessed via the Realtime API
2. Chain Method
A more modular and easy-to-start approach that works as Speech-to-text → LLM → Text-to-speech. Advantages of this method:
- Flexibility to mix and match components
- High reliability
- Ease of quickly converting a text-based agent to a voice agent
- Making existing text-based agents voice-enabled
Developers often prefer the chain approach because it’s modular, offers flexibility to mix and match components, and provides high reliability. It’s also easier to get started - an existing text-based agent can be taken, a speech-to-text model added to one side, a text-to-speech model to the other side, and immediately transformed into a voice agent.
With OpenAI’s Agents SDK, developers can now transform their text-based agents into voice agents with just a few lines of code. Here’s a code example:
# Voice agent creation example
from openai.agents import VoicePipeline, Workflow
# Existing text-based workflow
text_workflow = Workflow(...)
# Create voice pipeline
voice_agent = VoicePipeline(
workflow=text_workflow,
speech_to_text_model="gpt-4o-transcribe",
text_to_speech_model="gpt-4o-mini-tts",
text_to_speech_voice="onyx"
)
# Ready for audio streaming
audio_input = get_audio_from_user()
audio_response = voice_agent.run(audio_input)
play_audio(audio_response)
Application Areas
With these models, you can accomplish the following:
Customer Service and Business Applications
- Natural and empathetic customer support systems
- Call center automation and analysis
- Business meeting notes and transcripts
- Teleconference subtitles and summaries
Education and Language Learning
- Interactive language training partners
- Pronunciation coaching and feedback
- Speech practice and simulations
- Tools to increase student engagement
Content Creation
- Audiobook and podcast production
- Automatic video subtitling
- Dubbing and translation services
- Personal content narration and presentation
Accessibility
- Real-time transcription for the hearing impaired
- Audio descriptions for the visually impaired
- Voice interfaces for elderly users
- Customized interaction experiences for people with disabilities
API Usage and Integration
All these new audio models are now accessible via API. Different APIs that developers can use include:
API Types and Supported Modalities
| API | Supported Modalities | Streaming Support |
|---|---|---|
| Realtime API | Audio and text inputs and outputs | Audio streaming in and out |
| Chat Completions API | Audio and text inputs and outputs | Audio streaming out |
| Transcription API | Audio inputs | Audio streaming out |
| Speech API | Text inputs and audio outputs | Audio streaming out |
When to Use Which API?
- For real-time interactions or transcription → Realtime API
- For non-real-time but audio-based applications requiring features like function calling → Chat Completions API
- For single specific purpose use cases → Transcription, Translation, or Speech APIs
Pricing
- gpt-4o-transcribe: 0.6 cents per minute (same price as Whisper)
- gpt-4o-mini-transcribe: 0.3 cents per minute (half price!)
- gpt-4o-mini-tts: 1 cent per minute
What’s Coming in the Future?
OpenAI announced that they will continue to improve the intelligence and accuracy of their audio models. Also, in the future:
- Custom Voices: Ability for developers to integrate their own custom voices into the system (in accordance with safety standards)
- New Modalities: Investment in other modalities including video
- Multimodal Agents: Multimodal agent experiences combining text, audio, and visuals
- Safety Standards: Policies and tools for responsible use of synthetic voice technologies
OpenAI also continues to engage in dialogue with policymakers, researchers, developers, and creatives about the opportunities and challenges posed by synthetic voices.
Practical Application: Voice Agent Demo Project
Let’s look at a simple example shown in OpenAI’s live stream to see how a voice agent works:
// Simple websocket server code for a voice agent
const WebSocket = require("ws");
const { OpenAI, VoicePipeline } = require("openai");
const wss = new WebSocket.Server({ port: 8080 });
const openai = new OpenAI();
// Initialize audio buffer
let audioBuffer = Buffer.alloc(0);
wss.on("connection", (ws) => {
ws.on("message", async (message) => {
// Receiving audio data
if (message instanceof Buffer) {
// Concatenate audio chunks
audioBuffer = Buffer.concat([audioBuffer, message]);
} else if (message === "end") {
try {
// Voice agent pipeline
const voicePipeline = new VoicePipeline({
input: audioBuffer,
speechToTextModel: "gpt-4o-transcribe",
llmModel: "gpt-4o",
text_to_speech_model: "gpt-4o-mini-tts",
voice: "onyx",
});
// Return audio response as streaming
for await (const chunk of voicePipeline.stream()) {
ws.send(chunk);
}
} catch (error) {
console.error("Audio processing error:", error);
} finally {
// Reset buffer
audioBuffer = Buffer.alloc(0);
}
}
});
});
console.log("WebSocket voice agent server running on port 8080");
Conclusion
OpenAI’s new audio models represent a significant advancement in audio technology. These models increase speech recognition accuracy and provide more control in voice synthesis, allowing developers to create more natural and personalized audio experiences.
Comparison data, technical innovations, and demo codes prove that OpenAI is truly revolutionizing audio technology. With these models, you can go beyond text-based agents and design intelligent voice experiences that offer truly human-like interactions.
If you want to try these technologies yourself, you can visit openai.fm or start developing through the OpenAI API.
Note: When using OpenAI’s audio models, care should be taken to ensure that synthetic voices do not imitate real people’s voices. OpenAI monitors to ensure that audio models are limited to artificial, preset voices and that these voices consistently match synthetic presets.