
Hello Qwen3! A New Era in AI 🚀
The latest member of the Qwen family, Qwen3, makes a bold entry into the world of large language models (LLMs). Officially announced on May 4, 2025, it features hybrid reasoning modes, impressive multilingual support, and enhanced agent capabilities. The Qwen3 series appeals to a wide audience by offering both MoE (Mixture of Experts) and dense model options.
The flagship model, Qwen3-235B-A22B, delivers competitive performance in coding, mathematics, and general capabilities, rivaling top models like DeepSeek-R1, o1, o3-mini, Grok-3, and Gemini-2.5-Pro. The smaller MoE model, Qwen3-30B-A3B, outperforms QwQ-32B with 10x fewer active parameters, and even a small model like Qwen3-4B can match the performance of Qwen2.5-72B-Instruct.
Highlights:
- Hybrid Reasoning Modes: Step-by-step reasoning for complex problems or instant answers for quick responses.
- Broad Language Support: Full support for 119 languages and dialects.
- Advanced Agent Capabilities: Optimized for coding and agent tasks, with enhanced MCP support.
- Open Weights Policy: Two MoE and six dense models are open source under the Apache 2.0 license.
Qwen3 Model Family: Solutions for Every Need
The Qwen3 series offers a variety of models for different needs and resources:
MoE (Mixture of Experts) Models: Efficiency and Power Combined
| Model Name | Layers | Attention Heads (Q / KV) | Experts (Total / Active) | Context Length | Total Params | Active Params |
|---|---|---|---|---|---|---|
| Qwen3-30B-A3B | 48 | 32 / 4 | 128 / 8 | 128K | 30B | 3B |
| Qwen3-235B-A22B | 94 | 64 / 4 | 128 / 8 | 128K | 235B | 22B |
Dense Models: Performance at Different Scales
| Model Name | Layers | Attention Heads (Q / KV) | Tied Embedding | Context Length | Total Params |
|---|---|---|---|---|---|
| Qwen3-0.6B | 28 | 16 / 8 | Yes | 32K | 0.6B |
| Qwen3-1.7B | 28 | 16 / 8 | Yes | 32K | 1.7B |
| Qwen3-4B | 36 | 32 / 8 | Yes | 32K | 4B |
| Qwen3-8B | 36 | 32 / 8 | No | 128K | 8B |
| Qwen3-14B | 40 | 40 / 8 | No | 128K | 14B |
| Qwen3-32B | 64 | 64 / 8 | No | 128K | 32B |
| 128K | 32B |
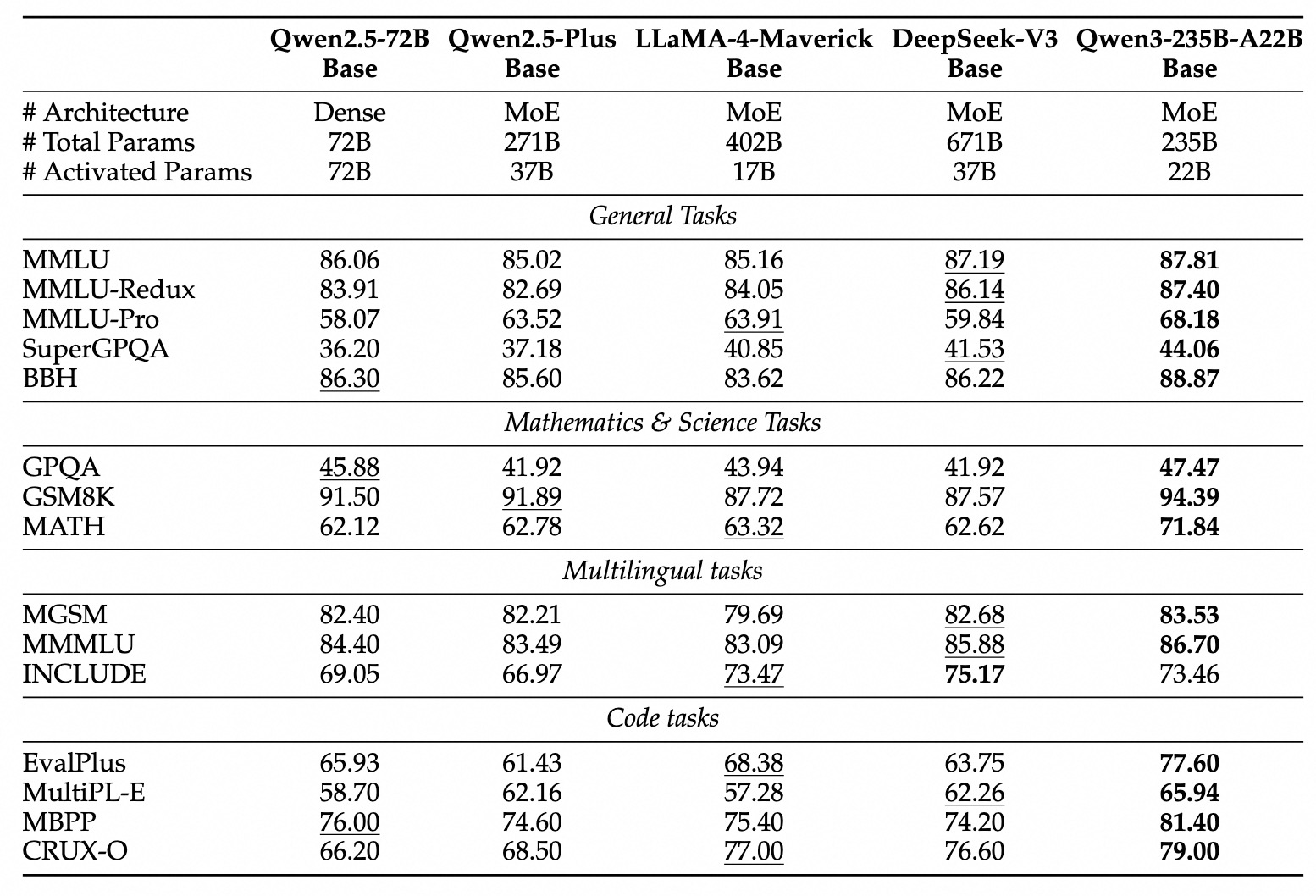
Note: Qwen3 dense base models perform as well as or better than Qwen2.5 base models with more parameters (e.g., Qwen3-32B-Base ≈ Qwen2.5-72B-Base). Qwen3-MoE base models achieve similar performance to Qwen2.5 dense base models with only 10% of the active parameters, providing significant cost advantages.

Key Features and Innovations
Hybrid Reasoning Modes: Flexible Problem Solving
Qwen3 introduces a hybrid approach to problem solving:
- Thinking Mode: The model reasons step by step for complex problems. Ideal for in-depth analysis.
- Non-Thinking Mode: The model provides instant answers for simple, speed-priority questions.
This flexibility allows users to control the “thinking” level required for the task. More importantly, the integration of these two modes greatly improves the model’s stable and efficient reasoning budget control. Users can configure budgets per task, making it easier to balance cost-effectiveness and inference quality.
Multilingual Support: Global Reach and Performance
Qwen3 models support 119 languages and dialects, opening new doors for international applications. This extensive coverage ensures that users worldwide can benefit from the model’s capabilities. Notably, its performance in less commonly used languages sets Qwen3 apart from its competitors.
Supported Languages and Dialects:
| Language Family | Languages |
|---|---|
| Indo-European | English, French, Portuguese, German, Romanian, Swedish, Danish, Bulgarian, Russian, Czech, Greek, Ukrainian, Spanish, Dutch, Slovak, Croatian, Polish, Lithuanian, Norwegian Bokmål, Norwegian Nynorsk, Persian, Slovenian, Gujarati, Latvian, Italian, Occitan, Nepali, Marathi, Belarusian, Serbian, Luxembourgish, Venetian, Assamese, Welsh, Silesian, Asturian, Chhattisgarhi, Awadhi, Maithili, Bhojpuri, Sindhi, Irish, Faroese, Hindi, Punjabi, Bengali, Oriya, Tajik, Eastern Yiddish, Lombard, Ligurian, Sicilian, Friulian, Sardinian, Galician, Catalan, Icelandic, Tosk Albanian, Limburgish, Dari, Afrikaans, Macedonian, Sinhala, Urdu, Magahi, Bosnian, Armenian |
| Sino-Tibetan | Chinese (Simplified, Traditional, Cantonese), Burmese |
| Afro-Asiatic | Arabic (Standard, Najdi, Levantine, Egyptian, Moroccan, Mesopotamian, Ta’izzi-Adeni, Tunisian), Hebrew, Maltese |
| Austronesian | Indonesian, Malay, Tagalog, Cebuano, Javanese, Sundanese, Minangkabau, Balinese, Banjar, Pangasinan, Iloko, Waray (Philippines) |
| Dravidian | Tamil, Telugu, Kannada, Malayalam |
| Turkic | Turkish, Northern Azerbaijani, Northern Uzbek, Kazakh, Bashkir, Tatar |
| Tai-Kadai | Thai, Lao |
| Uralic | Finnish, Estonian, Hungarian |
| Austroasiatic | Vietnamese, Khmer |
| Other | Japanese, Korean, Georgian, Basque, Haitian Creole, Papiamento, Kabuverdianu (Cape Verdean Creole), Tok Pisin, Swahili |
Note: This list is compiled from Qwen3’s official documentation. Some languages include dialects and variants.
Qwen3’s extensive language support provides high accuracy and fluency not only in widely spoken languages but also in less commonly used ones, offering a unique experience for global users. This feature is particularly advantageous for local content creation and multilingual projects.
Enhanced Agent Capabilities: Coding and Interaction
Qwen3 models are optimized for coding and agent capabilities. MCP (Model Context Protocol) support has also been enhanced. This enables the models to interact more effectively with their environment and handle complex tasks.
(See the original documentation for sample interactions.)
Technical Details: Training Process
Pre-training
The Qwen3 pre-training dataset is significantly expanded compared to Qwen2.5. About 36 trillion tokens (almost double Qwen2.5) were used, covering 119 languages and dialects. Data was collected not only from the web but also from PDF-like documents. Qwen2.5-VL was used to extract text from these documents, and Qwen2.5 was used to improve the quality of the extracted content. To increase math and code data, synthetic data such as textbooks, Q&A pairs, and code snippets were generated using Qwen2.5-Math and Qwen2.5-Coder.
The pre-training process consists of three stages:
- Stage 1 (S1): Over 30 trillion tokens and 4K context length to build basic language skills and general knowledge.
- Stage 2 (S2): Additional 5 trillion tokens with a higher proportion of knowledge-intensive data (STEM, coding, reasoning).
- Stage 3: High-quality long-context data to extend context length to 32K tokens.
Post-training
A four-stage training pipeline was used to develop the hybrid model capable of both step-by-step reasoning and fast responses:
- Long Chain-of-Thought (CoT) Cold Start: Models were fine-tuned with diverse long CoT data covering math, coding, logical reasoning, and STEM tasks to build core reasoning skills.
- Reasoning-based Reinforcement Learning (RL): RL with rule-based rewards and increased compute to improve exploration and exploitation.
- Thinking Mode Fusion: Non-thinking capabilities were integrated by fine-tuning the thinking model on a combination of long CoT data and commonly used instruction tuning data.
- General RL: RL was applied on 20+ general domain tasks (instruction following, format following, agent capabilities, etc.) to further enhance general abilities and correct undesired behaviors.
Try Qwen3 Live
You can try Qwen3 directly in your browser using the interactive panel below:
Developing with Qwen3 and Future Vision
Qwen3 models (both post-trained and pre-trained versions) are available on platforms like Hugging Face, ModelScope, and Kaggle. For deployment, frameworks like SGLang and vLLM are recommended; for local use, tools like Ollama, LMStudio, MLX, llama.cpp, and KTransformers are suggested.
The Qwen team aims to further improve model architectures and training methodologies, targeting data scaling, increasing model size, extending context length, broadening modalities, and advancing RL with environmental feedback for long-horizon reasoning. They believe we are moving from an era of training models to one of training agents, and the next iteration promises meaningful progress for everyone’s work and life.
You can try Qwen3 on Qwen Chat Web (chat.qwen.ai) and the mobile app!