

Önemli Not: Meta bugün yapay zeka tarihinde yeni bir sayfa açtı. Llama 4 serisi, çoklu modlu yapay zeka yetenekleri ve devrim niteliğindeki uzman karışımı mimarisiyle rakiplerini geride bırakıyor. İlk testlerde, GPT-4o ve Gemini 2.0 gibi önde gelen modelleri geride bırakmayı başarıyor!
Llama 4: Çoklu Modlu Yapay Zekada Bir Devrim 🚀
Meta, yapay zeka dünyasında yeni bir sayfa açacak Llama 4 modellerini resmen duyurdu. Bu yeni model ailesi, özellikle çoklu modlu yetenekleri ve uzman karışımı (MoE) mimarisiyle öne çıkıyor. Meta’nın açık ağırlıklı model yaklaşımını sürdüren Llama 4, hem performansı hem de erişilebilirliğiyle yapay zeka ekosisteminde önemli bir adımı temsil ediyor.
Bu yeni nesil Llama modelleri, yapay zekada üç büyük soruna etkili çözümler getiriyor:
- Verimlilik Sorunu: MoE mimarisiyle daha az kaynak kullanarak üstün performans
- Çoklu Modluluk Sorunu: Metin ve görsellerin doğal entegrasyonu
- Bağlam Penceresi Sorunu: 10 milyon token ile sınırsız bağlam yeteneği
Bilgi Kesme Tarihi: Ağustos 2024
Resmi Olarak Desteklenen Diller: Arapça, İngilizce, Fransızca, Almanca, Hintçe, Endonezce, İtalyanca, Portekizce, İspanyolca, Tagalogca, Tayca ve Vietnamca
Llama 4 Model Ailesi: Yeni Nesil Yapay Zekanın Üç Temel Taşı
Meta, Llama 4 serisinin ilk modelleri olarak üç farklı varyant sunuyor:
Llama 4 Scout: Tek GPU’da Çalışan Çoklu Modlu Zeka
- Aktif Parametreler: 17 milyar
- Uzman Sayısı: 16
- Toplam Parametreler: 109 milyar
- Bağlam Penceresi: 10 milyon token (sektör lideri)
- Eğitim Token Sayısı: ~40 trilyon
- Ana Özellik: Tek bir NVIDIA H100 GPU’da Int4 nicemleme ile çalışabilme yeteneği
Dikkat Çekici Özellik: Llama 4 Scout’un 10 milyon token bağlam penceresi, GPT-4’ün 128 bin token limitinden yaklaşık 80 kat daha büyük! Bu, bir kitabın tamamını, teknik dokümantasyonu veya saatlerce konuşma geçmişini tek seferde işleyebilme anlamına geliyor.
Performans Karşılaştırması: Llama 4 Scout, Gemma 3, Gemini 2.0 Flash-Lite ve Mistral 3.1 gibi benzer boyuttaki modelleri geniş bir yelpazedeki yaygın kıyaslamalarda geride bırakıyor.
Llama 4 Maverick: Sınıfının En İyisi
- Aktif Parametreler: 17 milyar
- Uzman Sayısı: 128
- Toplam Parametreler: 400 milyar
- Bağlam Penceresi: 1 milyon token
- Eğitim Token Sayısı: ~22 trilyon
- Ana Özellik: En üst düzey performans/maliyet oranı
Karşılaştırma: Llama 4 Maverick, parametre sayısının yarısıyla GPT-4o ve Gemini 2.0 Flash’ı geride bırakırken, DeepSeek v3 ile benzer performans gösteriyor. LMArena’da 1417 ELO puanı alan deneysel sohbet versiyonu, sınıfında en üst düzey başarıya ulaşıyor.
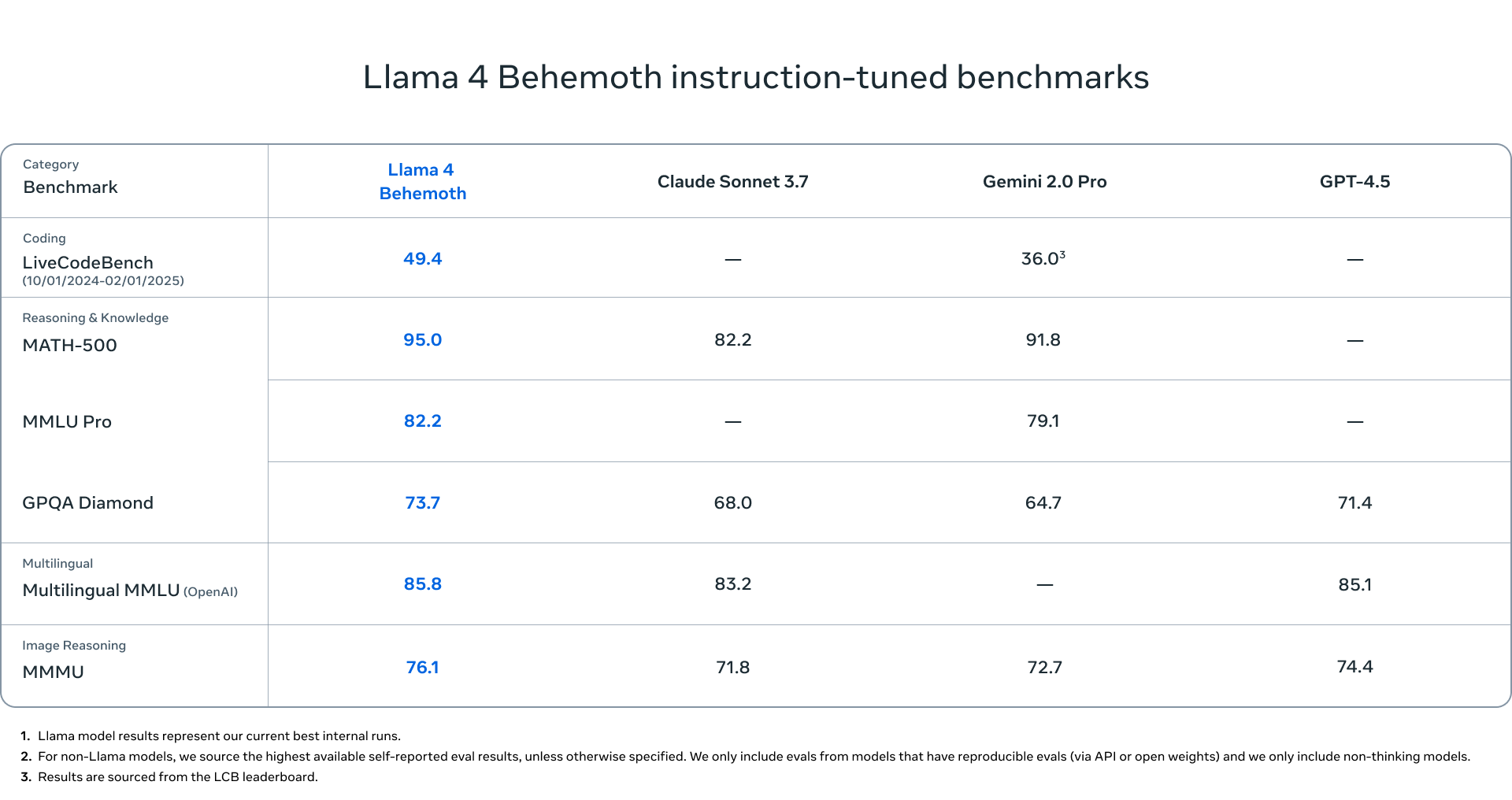
Llama 4 Behemoth: Meta’nın Dev Öğretmeni
- Aktif Parametreler: 288 milyar
- Uzman Sayısı: 16
- Toplam Parametreler: Yaklaşık 2 trilyon
- Ana Özellik: GPT-4.5 ve Claude Sonnet 3.7’ye kıyasla STEM alanlarında üstün performans
Not: Meta şu anda yaklaşık 2 trilyon parametreye sahip bu dev modeli yayınlamıyor çünkü eğitimi hala devam ediyor, ancak eğitim sürecinde küçük kardeşlerine “öğretmen” olarak hizmet ettiğini belirtiyor.
Mimarisi ve Teknik Yenilikler
Uzman Karışımı (MoE) Mimarisi: Akıllı İş Bölümü
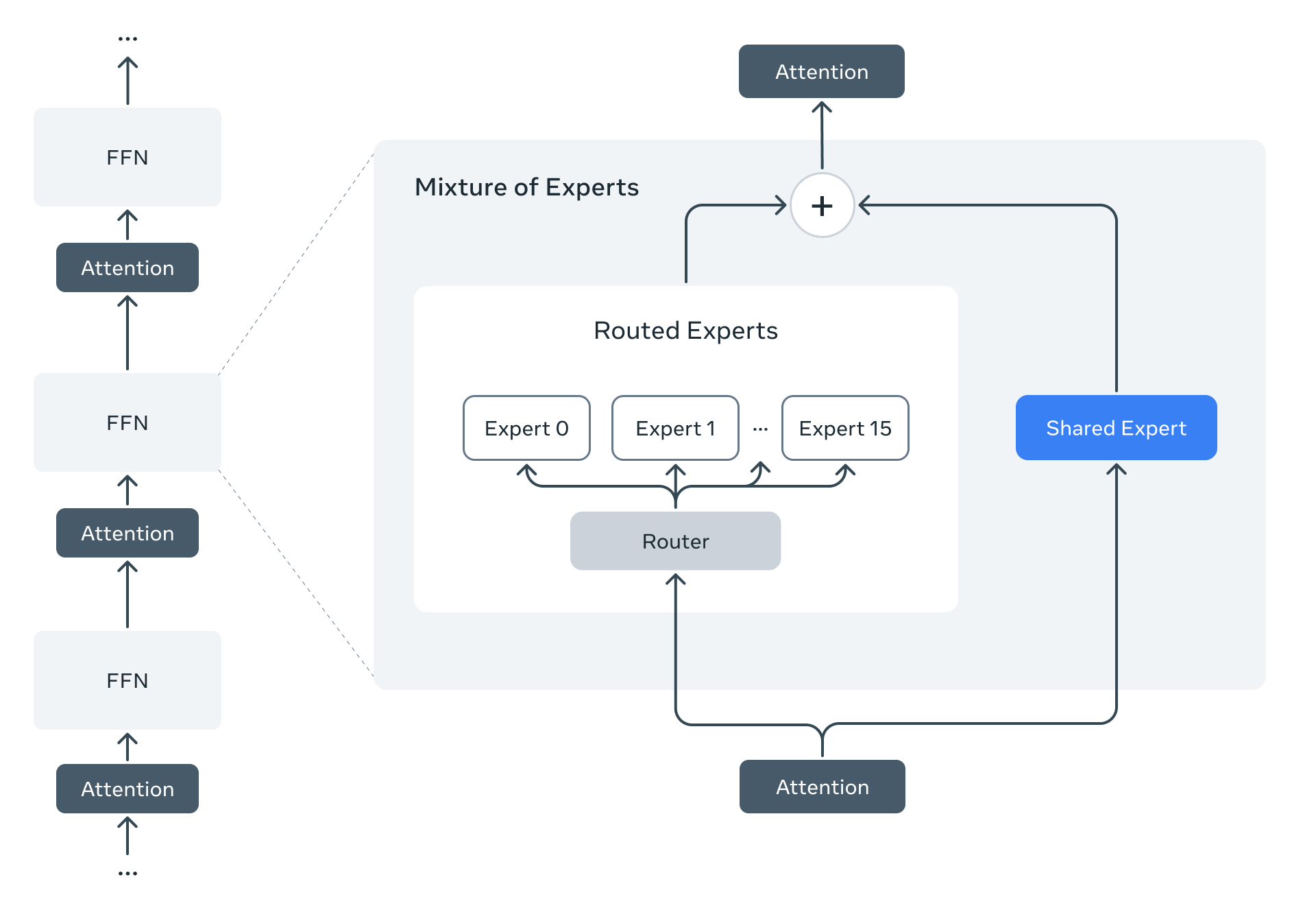
Llama 4 modelleri, Meta’nın MoE mimarisini kullandığı ilk modeller olarak öne çıkıyor. Bu mimari, toplam parametrelerin sadece bir kısmını token başına aktif hale getirerek inanılmaz bir verimlilik sağlıyor.
Örneğin, Llama 4 Maverick modelinde:
- 17 milyar aktif parametre
- 400 milyar toplam parametre
- MoE katmanları 128 yönlendirilmiş uzman + 1 paylaşılan uzman içeriyor
- Her token paylaşılan uzmanı VE 128 uzmandan sadece birini aktif hale getiriyor
- Bu, hesaplama maliyetini %95’e kadar azaltıyor!
Yerel Çoklu Modluluk: Görsel ve Metin Entegrasyonu
Llama 4 modelleri, metin ve görselleri ayrı ayrı işleyen diğer modellerden farklı olarak “erken füzyon” tekniğiyle doğal entegrasyon sağlıyor:
- Önceki Modeller: Görüntü → Görüntü Kodlayıcı → Metin Çevirisi → LLM → Yanıt
- Llama 4: Görüntü + Metin → Tek Model İşleme → Yanıt
Bu yaklaşım, görsellerin daha derin ve doğal anlaşılmasını sağlıyor ve modelin büyük miktarda etiketlenmemiş metin, görüntü ve video verisiyle ön eğitim yapmasına olanak tanıyor.
iRoPE: 10 Milyon Token Bağlamın Arkasındaki Sır
Llama 4 Scout’un devrim niteliğindeki 10 milyon token bağlam penceresini mümkün kılan teknik yenilik “iRoPE” mimarisi:
- i: “iç içe geçmiş” dikkat katmanları
- RoPE: Döner Konum Gömme
Bu mimari, konumsal gömme olmadan iç içe geçmiş dikkat katmanları kullanarak ve çıkarım sırasında dikkat sıcaklık ölçeklendirmesi uygulayarak teorik olarak sonsuz bağlamı mümkün kılıyor.
Performans ve Karşılaştırmalar: Rakipleri Nasıl Geride Bırakıyor? 📊
Ön Eğitimli Modeller Karşılaştırması
| Kategori | Kıyaslama | Metrik | Llama 3.1 70B | Llama 3.1 405B | Llama 4 Scout | Llama 4 Maverick |
|---|---|---|---|---|---|---|
| Akıl Yürütme & Bilgi | MMLU | doğruluk | 79.3 | 85.2 | 79.6 | 85.5 |
| MMLU-Pro | doğruluk | 53.8 | 61.6 | 58.2 | 62.9 | |
| MATH | pass@1 | 41.6 | 53.5 | 50.3 | 61.2 | |
| Kodlama | MBPP | pass@1 | 66.4 | 74.4 | 67.8 | 77.6 |
| Çok Dilli | TydiQA | ortalama/f1 | 29.9 | 34.3 | 31.5 | 31.7 |
| Görüntü | ChartQA | doğruluk | Çoklu mod desteği yok | 83.4 | 85.3 | |
| DocVQA | anls | 89.4 | 91.6 | |||
Dikkat Çekici Sonuç: Llama 4 Maverick, matematikte (MATH kıyaslaması) Llama 3.1 405B modelinden %14.4 daha iyi performans gösteriyor - aktif parametrelerin yarısından azını kullanarak!
Talimat Ayarlı Modeller Karşılaştırması
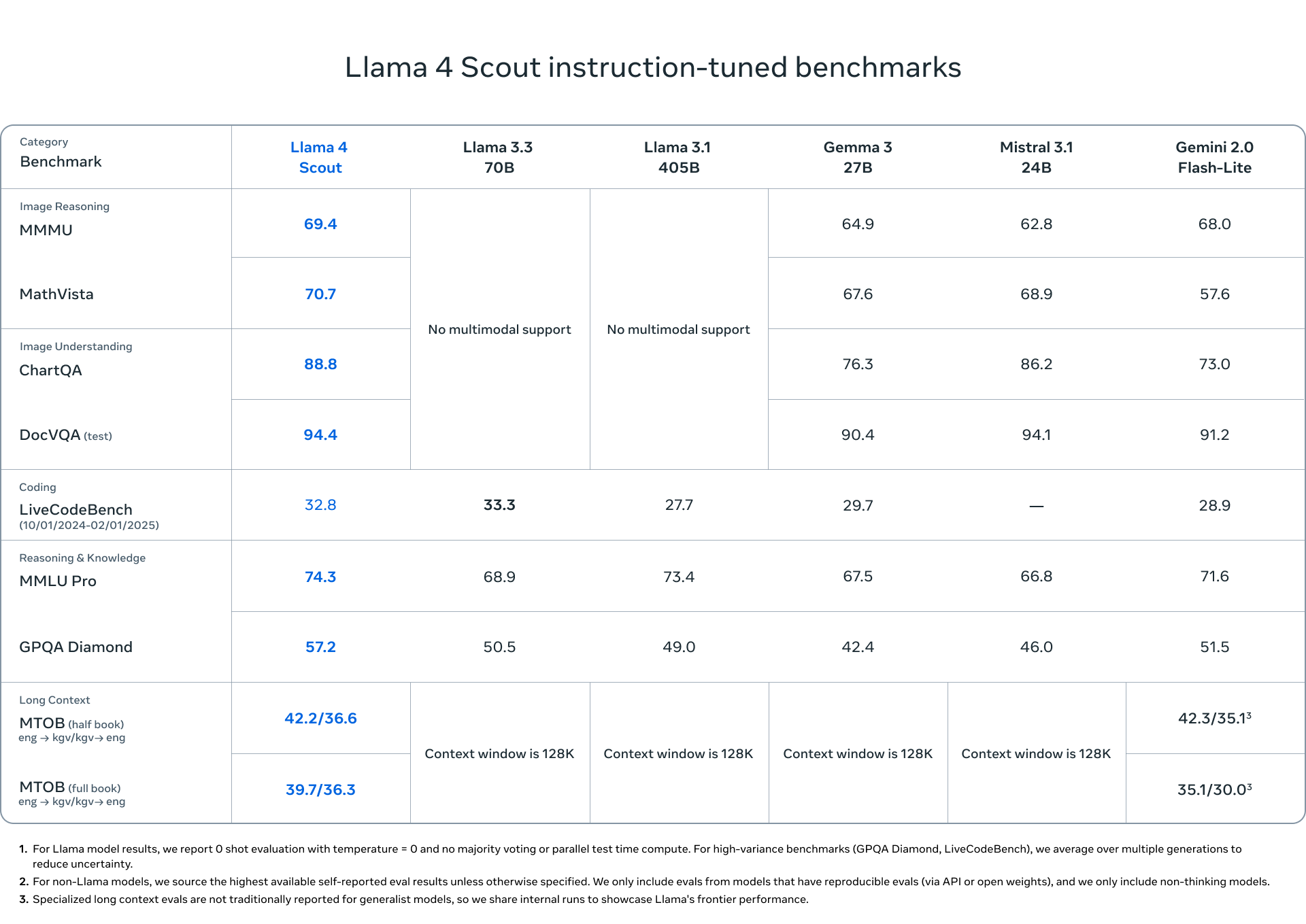
| Kategori | Kıyaslama | Metrik | Llama 3.3 70B | Llama 3.1 405B | Llama 4 Scout | Llama 4 Maverick |
|---|---|---|---|---|---|---|
| Görsel Akıl Yürütme | MMMU | doğruluk | Çoklu mod desteği yok | 69.4 | 73.4 | |
| MMMU Pro | doğruluk | 52.2 | 59.6 | |||
| MathVista | doğruluk | 70.7 | 73.7 | |||
| Görsel Anlama | ChartQA | doğruluk | 88.8 | 90.0 | ||
| DocVQA (test) | anls | 94.4 | 94.4 | |||
| Kodlama | LiveCodeBench (10/01/2024-02/01/2025) |
pass@1 | 33.3 | 27.7 | 32.8 | 43.4 |
| Akıl Yürütme & Bilgi | MMLU Pro | doğruluk | 68.9 | 73.4 | 74.3 | 80.5 |
| GPQA Diamond | doğruluk | 50.5 | 49.0 | 57.2 | 69.8 | |
| Çok Dilli | MGSM | ortalama/em | 91.1 | 91.6 | 90.6 | 92.3 |
| Uzun Bağlam | MTOB (yarım kitap) eng->kgv/kgv->eng |
chrF | Bağlam penceresi 128K | 42.2/36.6 | 54.0/46.4 | |
| MTOB (tam kitap) eng->kgv/kgv->eng |
chrF | 39.7/36.3 | 50.8/46.7 | |||
Çarpıcı Sonuç: Llama 4 Maverick, son derece zorlu GPQA Diamond kıyaslamasında Llama 3.3 70B modelinden %38.2 daha iyi performans gösteriyor ve literatürden ileri düzey fizik ve matematik sorularını çözmede büyük bir sıçrama yapıyor!
Gerçek Dünya Performansı: Llama 4 Neyi Değiştiriyor? 📱
Llama 4’ün yenilikleri pratikte ne anlama geliyor? İşte dikkat çeken kullanım alanları:
1. Görsel Anlama ve Açıklama
Llama 4, karmaşık görselleri anlama ve açıklama konusunda yeni bir çığır açıyor:
- Tıbbi Görüntüler: MRI, röntgen ve diğer tıbbi görüntülerde anormallikleri tespit etme yeteneği
- Grafikler ve Tablolar: İş raporlarındaki karmaşık grafikleri analiz etme ve özetleme yeteneği
- Teknik Diyagramlar: Mimari çizimleri, devre diyagramları ve teknik çizimleri anlama yeteneği
2. Ultra-Uzun Bağlam Yetenekleri
10 milyon token bağlam penceresiyle:
- Tüm Kitapları Anlama: Bir romanı veya teknik kitabı bütün olarak işleme ve tartışabilme yeteneği
- Kod Tabanı Analizi: Milyonlarca satır kod içeren projeleri kapsamlı olarak analiz etme yeteneği
- Kişiselleştirilmiş Öğrenme: Öğrencinin tüm öğrenme geçmişini hatırlayarak kişiselleştirilmiş eğitim sunma yeteneği
Somut Örnek: Llama 4 Scout, 625 sayfalık “Savaş ve Barış” romanını tek seferde okuyup analiz edebilir ve aynı zamanda romanın başındaki ve sonundaki karakterlerin gelişimini karşılaştırabilir - hiçbir bağlam kaybı yaşamadan!
Eğitim Süreci ve Teknik Detaylar 🛠️
MetaP: Hiper-parametre Optimizasyonunda Devrim
Meta, Llama 4 modelleri için geliştirdiği “MetaP” tekniğiyle kritik model hiper-parametrelerini güvenilir şekilde ayarlıyor. Bu teknik:
- Katman başına öğrenme oranlarını otomatik olarak belirliyor
- Başlatma ölçeklerini optimize ediyor
- Farklı toplu iş boyutları, model genişlikleri ve derinlikleri için aktarılabilir sonuçlar üretiyor
Eğitim Verisi Karışımı
Llama 4 modelleri için kullanılan veri karışımı:
- Toplam Token: 30+ trilyon (Llama 3’ün 2 katı)
- Dil Kapsamı: 200+ dil (100’den fazla dilde 1 milyar+ token)
- Veri Türleri: Metin, görüntü, video kareleri
- Veri Kaynakları: Kamu verisi, lisanslı içerik, Instagram ve Facebook’tan kamuya açık gönderiler
- Eğitim Hesaplaması: Llama 4 Scout 5.0M GPU saatini, Maverick ise H100-80GB donanımında 2.38M GPU saatini kullandı
- Çevresel Etki: Meta, yoğun eğitime rağmen net sıfır sera gazı emisyonunu koruyarak 0 piyasa bazlı emisyonla sonuçlandı
Eğitim Süreci ve Model Damıtma
Meta, daha küçük modellerin performansını artırmak için özel bir damıtma stratejisi kullanıyor:
- Behemoth Eğitimi: Önce 2 trilyon parametreli Behemoth modeli eğitiliyor
- Eş Damıtma: Behemoth modeli, bilgiyi Scout ve Maverick modellerine aktarmak için “öğretmen” olarak kullanılıyor
- Dinamik Ağırlıklandırma: Eğitim sırasında yumuşak ve sert hedeflerin dinamik ağırlıklandırılması
İlginç Not: Meta’nın araştırmacıları, Behemoth model eğitimi için SFT verilerinin %95’ini elemek zorunda kaldı. Daha küçük modeller için bu oran %50’ydi. Bu, daha büyük modellerin “daha seçici” olduğunu gösteriyor!
Çoklu Tur Pekiştirmeli Öğrenme
Meta, model eğitiminde çoklu tur pekiştirmeli öğrenme (RL) stratejisini şu şekilde kullanıyor:
- Zorluk Tespiti: pass@k analiziyle zor talimatları belirleme
- Dinamik Filtreleme: Eğitim sırasında sıfır avantaj değerine sahip talimatları dinamik olarak filtreleme
- Karışık Yetenek Grupları: Aynı eğitim toplu işinde farklı yeteneklerden talimatları birleştirme
Bu stratejiler, özellikle matematik, akıl yürütme ve kodlama yeteneklerinde önemli performans iyileştirmeleri sağlıyor.
Güvenlik ve Koruma Önlemleri: Güçlü ve Sorumlu Yapay Zeka 🛡️
Meta, Llama 4 modellerini geliştirirken kapsamlı güvenlik önlemleri aldı:
Model Seviyesinde İyileştirmeler
- Kırmızı Takım: Siber güvenlik ve düşmanca makine öğrenmesi uzmanları sistematik testler yaptı
- GOAT (Generative Offensive Agent Testing): Çoklu tur etkileşimleri simüle eden yeni bir güvenlik testi yaklaşımı
- Dengeli Siyasi Tutum: Llama 4’te, siyasi ve sosyal konularda yanıt reddetme oranı %7’den %2’nin altına düşürüldü
Açık Kaynak Güvenlik Araçları
Meta ayrıca Llama 4 ile kullanılabilecek açık kaynak güvenlik araçları sunuyor:
| Araç | İşlev | Kullanım Alanı |
|---|---|---|
| Llama Guard | Girdi/çıktı güvenliğini kontrol eder | Zararlı içerik tespiti |
| Prompt Guard | Kötü niyetli talimat tespiti | Talimat enjeksiyonu koruması |
| CyberSecEval | Siber güvenlik risk analizi | Yapay zeka güvenlik değerlendirmesi |
Güvenlik Test Odak Alanları
Meta özellikle üç kritik risk alanına odaklandı:
-
CBRNE (Kimyasal, Biyolojik, Radyolojik, Nükleer ve Patlayıcı Malzemeler)
- Modelin silahlaştırma potansiyelini değerlendiren uzman testleri
- Çeşitli saldırı vektörlerine karşı dayanıklılık testleri
-
Çocuk Güvenliği
- Çoklu modlu ve çok dilli çocuk güvenliği değerlendirmeleri
- İçerik filtreleme ve veri güvenliği stratejileri
-
Siber Saldırı Yeteneği
- Siber saldırı otomasyon yeteneklerinin değerlendirilmesi
- Güvenlik açıklarını tespit etme ve sömürme yeteneklerinin test edilmesi
Sonuç: Meta’nın kapsamlı güvenlik değerlendirmelerine göre, Llama 4 modelleri felaketle sonuçlanabilecek siber sonuçlara yol açabilecek riskleri artırmıyor.
Llama 4’ün Uygulama Alanları: Sınırsız Potansiyel 🌐
Sektöre Göre Kullanım Senaryoları
Yazılım Geliştirmede Devrim
Llama 4 Maverick’in LiveCodeBench’te %43.4 pass@1 oranıyla kodlamadaki başarısı, yazılım geliştirme süreçlerini dönüştürme potansiyeline sahip:
- Tam Proje Analizi: 10M token bağlam penceresiyle tüm kod tabanında çalışabilme yeteneği
- Kod Optimizasyonu: Mevcut kodu daha verimli hale getirme
- Mimari Tasarım: Sistem mimarisini önerme ve tasarımda yardımcı olma
- Hata Ayıklama: Karmaşık hataların kaynaklarını belirleme
Sağlık ve Tıpta Çığır Açan Yetenekler
Çoklu modlu yetenekleriyle Llama 4, sağlık sektöründe:
- Tıbbi Görüntü Analizi: MRI, röntgen ve diğer tıbbi görüntülerde anormallikleri tespit etme
- Hasta Kaydı Analizi: Uzun hasta geçmişlerini analiz ederek teşhis ve tedavi önerileri sunma
- Tıbbi Literatür İnceleme: Binlerce araştırma makalesini tarayarak kanıta dayalı tıbbi uygulamaları önerme
Görsel İşleme Yeteneği: Llama 4 modelleri, mükemmel sonuçlarla 5 giriş görüntüsüne kadar kapsamlı olarak test edildi, bu da onları çoklu görüntü analiz görevleri için güvenilir kılıyor.
Eğitimde Kişiselleştirilmiş Deneyim
10M token uzunluğundaki bağlam penceresi sayesinde:
- Kişiselleştirilmiş Öğrenme: Öğrencinin tüm öğrenme geçmişini hatırlayarak özel içerik sunma
- Ders Planı Oluşturma: Öğrencinin güçlü ve zayıf yönlerine göre özelleştirilmiş ders planları
- Çoklu Modlu Öğretim: Metinler, görsel açıklamalar ve grafiklerle karmaşık konuları açıklama yeteneği
İş Dünyasında Veri Analitiği
İş dünyasında çoklu modlu yetenekler ve uzun bağlam:
- Finansal Analiz: Uzun vadeli finansal raporların, grafiklerin ve tabloların bütünsel analizi
- Pazar Araştırması: Büyük miktarda metin ve görsel veriyi analiz ederek pazar trendlerini belirleme
- Belge Anlama: Karmaşık sözleşmeleri, politikaları ve raporları analiz etme
Geleceğe Bakış: Llama Ekosisteminin Yükselişi 🔮
Meta, Llama 4 serisiyle yapay zeka ekosistemini genişletmeye devam ediyor:
- LlamaCon Etkinliği: Llama 4 hakkında daha fazla detay 29 Nisan’da açıklanacak
- Açık Ekosistem: Meta, açık kaynak yaklaşımıyla daha fazla yeniliği desteklemeye devam ediyor
- Erişilebilirlik: Llama 4’e WhatsApp, Messenger, Instagram Direct üzerinden Meta AI ile erişim
Son Söz: Llama 4, çoklu modlu yetenekleri, uzun bağlam penceresi ve verimli MoE mimarisiyle yapay zeka alanında yeni bir çağ başlatıyor. Meta’nın açık ekosistem yaklaşımıyla birleştiğinde, bu gelişmeler önümüzdeki yıllarda yapay zeka alanında tamamen farklı bir manzara vaat ediyor.
API Fiyatlandırması ve Maliyet Karşılaştırması 💰
Meta’nın agresif fiyatlandırma stratejisi, Llama 4 modellerini sadece teknik olarak etkileyici değil, aynı zamanda rakipleriyle karşılaştırıldığında ekonomik olarak da çekici kılıyor:
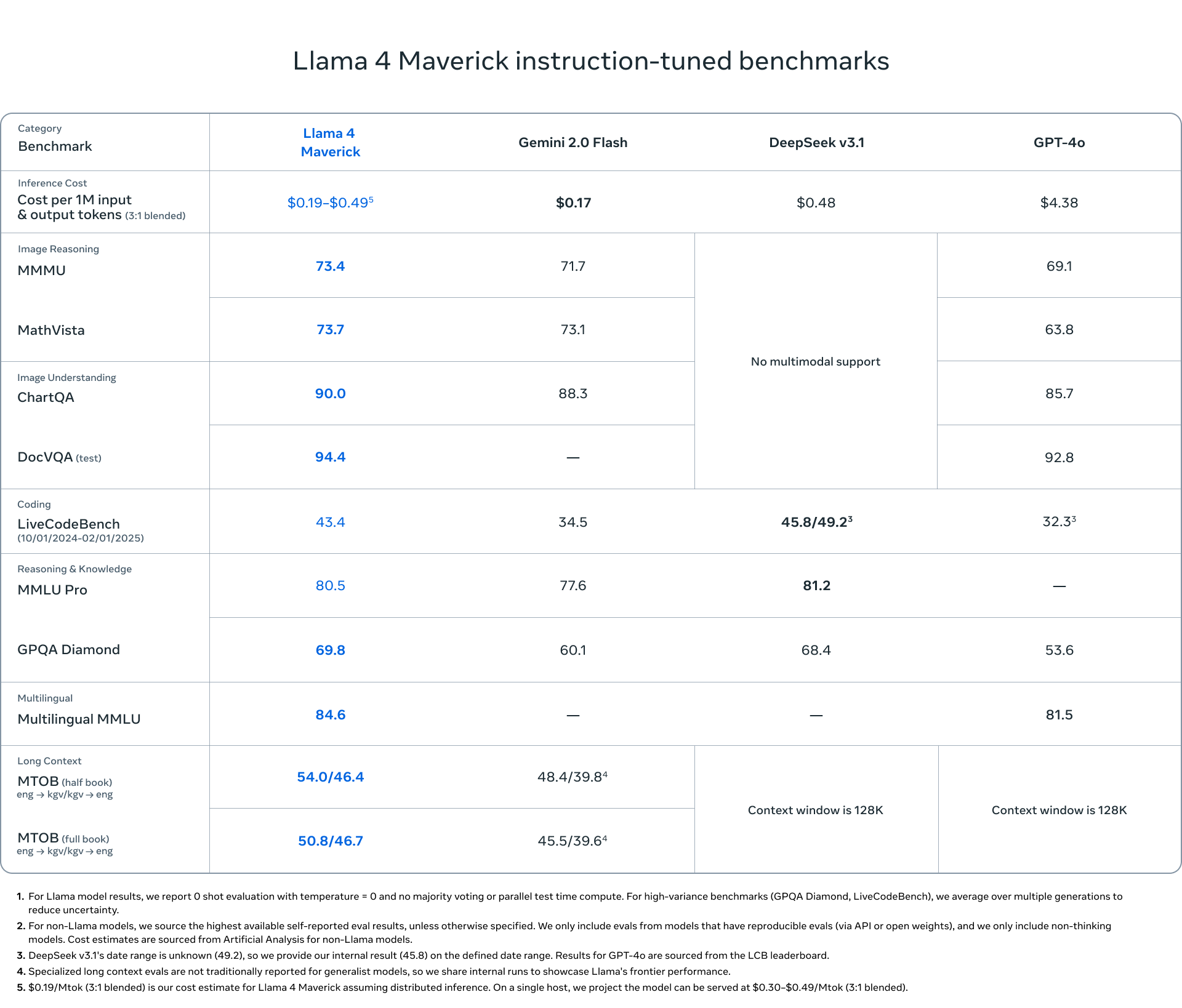
Llama 4 Maverick: Maliyetin Çok Altında Premium Performans
| Model | 1M token başına maliyet (3:1 girdi/çıktı karışımı) | MMMU | GPQA Diamond | LiveCodeBench |
|---|---|---|---|---|
| Llama 4 Maverick | $0.19-$0.49 | 73.4 | 69.8 | 43.4 |
| GPT-4o | $4.38 (23 kat daha pahalı) | 69.1 | 53.6 | 32.3 |
| Gemini 2.0 Flash | $0.17 | 71.7 | 60.1 | 34.5 |
| DeepSeek v3.1 | $0.48 | Çoklu mod desteği yok | 68.4 | 45.8/49.2 |
Fiyat-Performans Analizi: Llama 4 Maverick, GPT-4o’nun sadece ~1/23’ü maliyetle üstün performans sunarak, kurumsal dağıtımlar için son derece uygun maliyetli bir seçenek haline geliyor. Dağıtılmış çıkarım çalıştırıldığında, maliyet milyon token başına $0.19’a kadar düşebiliyor.
Llama 4 Scout: Tek GPU Verimliliği
Scout’un API fiyatlandırması henüz açıklanmadı, ancak Int4 nicemleme ile tek bir H100 GPU’da çalışabilme yeteneği, sınıfındaki benzer modellerle karşılaştırıldığında onu son derece kaynak verimli kılıyor. Kuruluşlar, rakip modellere kıyasla önemli ölçüde daha düşük donanım gereksinimleriyle onu şirket içinde dağıtabilir.
Kurumsal Maliyet Optimizasyonu: Aylık milyarlarca token işleyen büyük ölçekli dağıtımlar için, GPT-4o’dan Llama 4 Maverick’e geçiş, maliyetlerde %95’in üzerinde tasarruf sağlayabilir, bu da yüksek hacimli kullanıcılar için yıllık milyonlarca dolara kadar çıkabilir.
Hemen Deneyin! 🚀
- Llama 4 Scout ve Maverick modelleri artık llama.com ve Hugging Face’den indirilebilir
- Llama 4’ü WhatsApp, Messenger ve web üzerinden Meta AI ile hemen deneyebilirsiniz
- Geliştiriciler ayrıca Llama Guard, Prompt Guard ve CyberSecEval gibi güvenlik araçlarına erişebilir
Meta, bu makalede bahsedilen Llama 4 modellerini ve özelliklerini 5 Nisan 2025’te resmen duyurdu. Model özellikleri ve performansı gelecekte değişebilir. Bu blog, yeni gelişmeler veya hata düzeltmeleri ile güncellenebilir.