
Merhaba Qwen3! Yapay Zekada Yeni Dönem 🚀
Qwen ailesinin en son üyesi Qwen3, 4 Mayıs 2025’te duyuruldu. Büyük dil modelleri (LLM) dünyasına iddialı bir giriş yapan Qwen3, hibrit düşünme modları, etkileyici çoklu dil desteği ve geliştirilmiş ajan yetenekleriyle öne çıkıyor. Qwen3 serisi, hem MoE (Uzman Karışımı) hem de yoğun (dense) model seçenekleri sunarak geniş bir kullanıcı kitlesine hitap ediyor.
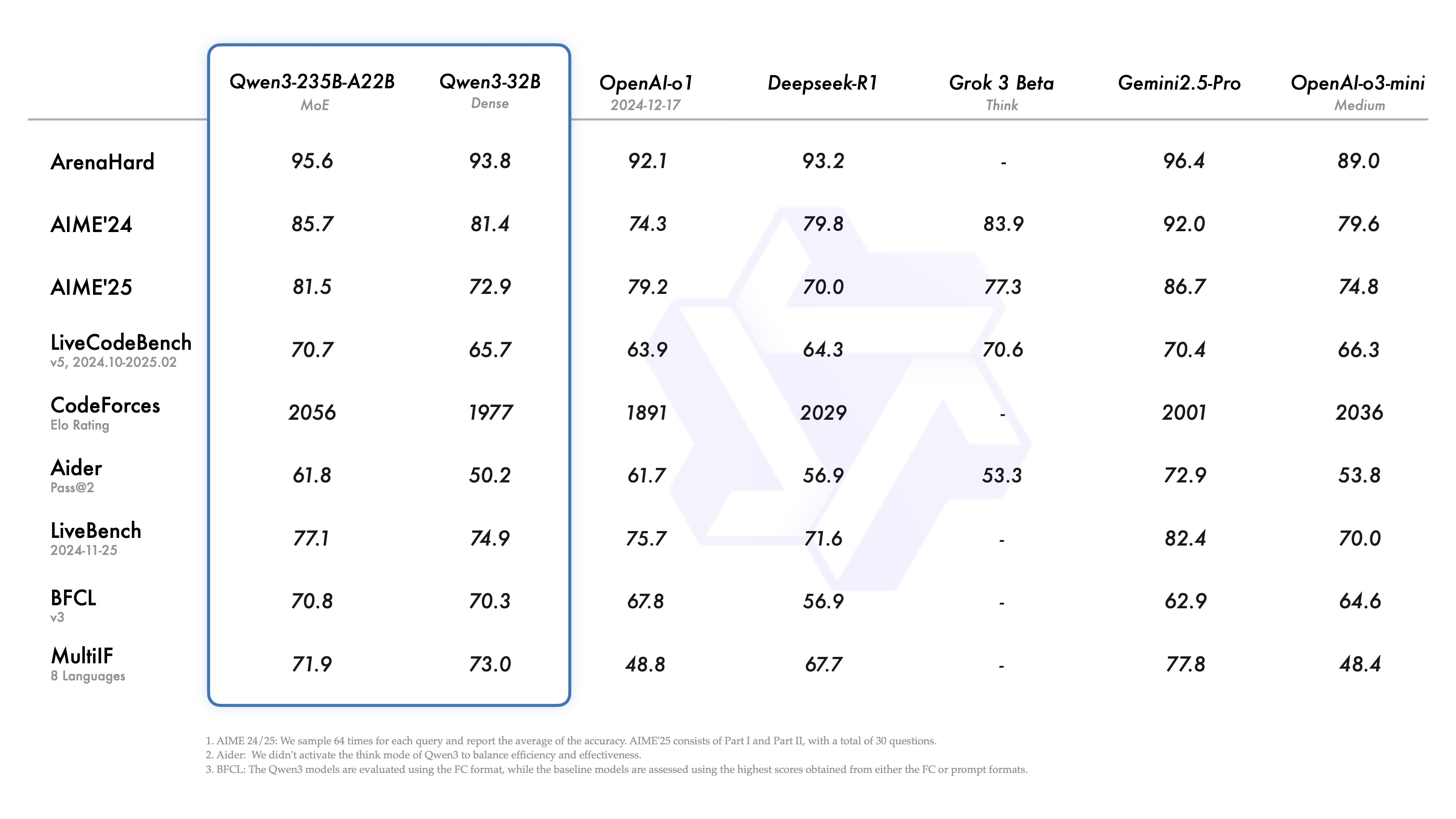
Amiral gemisi modeli Qwen3-235B-A22B, kodlama, matematik ve genel yetenekler gibi alanlarda DeepSeek-R1, o1, o3-mini, Grok-3 ve Gemini-2.5-Pro gibi zirvedeki modellerle rekabet edebilecek düzeyde performans sergiliyor. Daha küçük MoE modeli Qwen3-30B-A3B ise QwQ-32B’yi 10 kat daha az aktif parametreyle geride bırakırken, Qwen3-4B gibi küçük bir model bile Qwen2.5-72B-Instruct performansına rakip olabiliyor.
Öne Çıkanlar:
- Hibrit Düşünme Modları: Karmaşık problemler için adım adım düşünme veya hızlı yanıtlar için anlık cevap modu.
- Geniş Dil Desteği: Tam 119 dil ve lehçe desteği.
- Gelişmiş Ajan Yetenekleri: Kodlama ve ajan görevlerinde optimize edilmiş performans, MCP desteği güçlendirildi.
- Açık Ağırlık Politikası: İki MoE ve altı yoğun model Apache 2.0 lisansıyla açık kaynak olarak sunuluyor.
Qwen3 Model Ailesi: İhtiyaca Özel Çözümler
Qwen3 serisi, farklı ihtiyaçlara ve kaynaklara uygun çeşitli modeller sunuyor:
MoE (Uzman Karışımı) Modelleri: Verimlilik ve Güç Bir Arada
| Model Adı | Katman Sayısı | Dikkat Başlıkları (Q / KV) | Uzman Sayısı (Toplam / Aktif) | Bağlam Uzunluğu | Toplam Parametre | Aktif Parametre |
|---|---|---|---|---|---|---|
| Qwen3-30B-A3B | 48 | 32 / 4 | 128 / 8 | 128K | 30 Milyar | 3 Milyar |
| Qwen3-235B-A22B | 94 | 64 / 4 | 128 / 8 | 128K | 235 Milyar | 22 Milyar |
Yoğun (Dense) Modeller: Farklı Ölçeklerde Performans
| Model Adı | Katman Sayısı | Dikkat Başlıkları (Q / KV) | Gömme Bağlama (Tie Embedding) | Bağlam Uzunluğu | Toplam Parametre |
|---|---|---|---|---|---|
| Qwen3-0.6B | 28 | 16 / 8 | Evet | 32K | 0.6 Milyar |
| Qwen3-1.7B | 28 | 16 / 8 | Evet | 32K | 1.7 Milyar |
| Qwen3-4B | 36 | 32 / 8 | Evet | 32K | 4 Milyar |
| Qwen3-8B | 36 | 32 / 8 | Hayır | 128K | 8 Milyar |
| Qwen3-14B | 40 | 40 / 8 | Hayır | 128K | 14 Milyar |
| Qwen3-32B | 64 | 64 / 8 | Hayır | 128K | 32 Milyar |
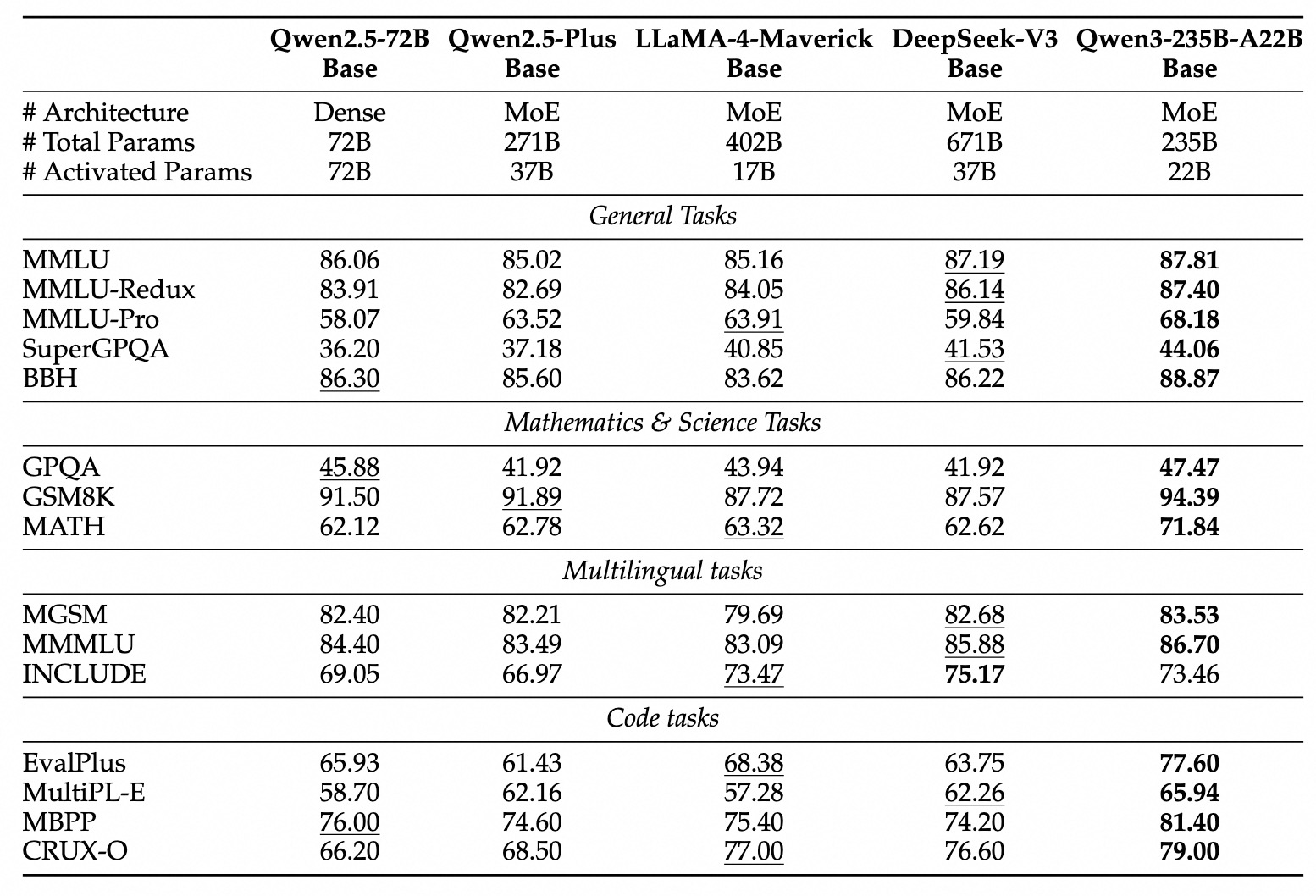
Not: Qwen3 yoğun temel modelleri, daha fazla parametreye sahip Qwen2.5 temel modelleriyle benzer veya daha iyi performans gösteriyor (örn. Qwen3-32B-Base ≈ Qwen2.5-72B-Base). Qwen3-MoE temel modelleri ise Qwen2.5 yoğun temel modelleriyle benzer performansı %10 aktif parametreyle yakalayarak önemli maliyet avantajı sağlıyor.

Anahtar Özellikler ve Yenilikler
Hibrit Düşünme Modları: Esnek Problem Çözme
Qwen3, problem çözmeye hibrit bir yaklaşım getiriyor:
- Düşünme Modu (Thinking Mode): Model, karmaşık problemler için adım adım mantık yürüterek sonuca ulaşır. Derinlemesine analiz gerektiren durumlar için idealdir.
- Düşünmeme Modu (Non-Thinking Mode): Model, hızın öncelikli olduğu basit sorular için anında yanıtlar üretir.
Bu esneklik, kullanıcıların görevin gerektirdiği “düşünme” seviyesini kontrol etmelerini sağlar. Daha da önemlisi, bu iki modun entegrasyonu, modelin kararlı ve verimli düşünme bütçesi kontrolü uygulamasını büyük ölçüde geliştirir. Kullanıcılar, görev özelinde bütçeler yapılandırarak maliyet etkinliği ve çıkarım kalitesi arasında optimum dengeyi daha kolay kurabilirler.
Çoklu Dil Desteği: Küresel Erişim ve Performans
Qwen3 modelleri, 119 dil ve lehçeyi destekleyerek uluslararası uygulamalar için yeni kapılar aralıyor. Bu geniş kapsam, dünya çapındaki kullanıcıların modelin gücünden faydalanmasını sağlıyor. Özellikle az kullanılan dillerdeki performansı, Qwen3’ü rakiplerinden ayıran önemli bir özellik olarak öne çıkıyor.
Desteklenen Diller ve Lehçeler:
| Dil Ailesi | Diller |
|---|---|
| Hint-Avrupa Dilleri | İngilizce, Fransızca, Portekizce, Almanca, Rumence, İsveççe, Danca, Bulgarca, Rusça, Çekçe, Yunanca, Ukraynaca, İspanyolca, Hollandaca, Slovakça, Hırvatça, Lehçe, Litvanca, Norveççe Bokmål, Norveççe Nynorsk, Farsça, Slovence, Gujarati, Letonca, İtalyanca, Oksitanca, Nepalce, Marathi, Beyaz Rusça, Sırpça, Lüksemburgca, Venedikçe, Assamca, Galce, Silezce, Asturyaca, Chhattisgarhi, Awadhi, Maithili, Bhojpuri, Sindhi, İrlandaca, Faroece, Hintçe, Pencapça, Bengalce, Oriya, Tacikçe, Doğu Yidiş, Lombardca, Liguryaca, Sicilyaca, Friulice, Sardunyaca, Galiçyaca, Katalanca, İzlandaca, Tosk Arnavutçası, Limburgca, Dari, Afrikanca, Makedonca, Sinhala, Urduca, Magahi, Boşnakça, Ermenice |
| Sino-Tibet Dilleri | Çince (Basitleştirilmiş, Geleneksel, Kantonca), Birmanca |
| Afro-Asyatik Diller | Arapça (Standart, Necdi, Levanten, Mısır, Fas, Mezopotamya, Ta’izzi-Adeni, Tunus), İbranice, Maltaca |
| Avustronezya Dilleri | Endonezce, Malayca, Tagalog, Cebuano, Cava Dili, Sundaca, Minangkabau, Balice, Banjar, Pangasinan, Iloko, Waray (Filipinler) |
| Dravid Dilleri | Tamilce, Teluguca, Kannada, Malayalam |
| Türk Dilleri | Türkçe, Kuzey Azerice, Kuzey Özbekçe, Kazakça, Başkurtça, Tatarca |
| Tai-Kadai Dilleri | Tayca, Laosça |
| Ural Dilleri | Fince, Estonca, Macarca |
| Austroasiatic Diller | Vietnamca, Kmerce |
| Diğer | Japonca, Korece, Gürcüce, Baskça, Haiti Kreyolü, Papiamento, Kabuverdianu, Tok Pisin, Svahili |
Not: Liste Qwen3’ün resmi dökümantasyonundan derlenmiştir. Bazı dillerin lehçeleri ve varyantları da kapsam dahilindedir.
Qwen3’ün bu geniş dil desteği, sadece yaygın dillerde değil, aynı zamanda az kullanılan dillerde de yüksek doğruluk ve akıcılık sunarak, küresel kullanıcılar için eşsiz bir deneyim sağlar. Bu özellik, özellikle yerel içerik üretimi ve çok dilli projeler için büyük bir avantaj sunar.
Geliştirilmiş Ajan Yetenekleri: Kodlama ve Etkileşim
Qwen3 modelleri, kodlama ve ajan yetenekleri açısından optimize edilmiştir. Ayrıca MCP (Model Context Protocol) desteği de güçlendirilmiştir. Bu sayede modeller, çevreleriyle daha etkin etkileşim kurabilir ve karmaşık görevleri yerine getirebilir.
(Örnek etkileşimler için orijinal dokümandaki görsellere başvurulabilir.)
Qwen3’ü Canlı Deneyin
Aşağıdaki interaktif panel üzerinden Qwen3’ü doğrudan tarayıcınızda deneyebilirsiniz:
Teknik Detaylar: Eğitim Süreci
Ön Eğitim (Pre-training)
Qwen3’ün ön eğitim veri seti, Qwen2.5’e kıyasla önemli ölçüde genişletilmiştir. Yaklaşık 36 trilyon token (Qwen2.5’in neredeyse iki katı) kullanılmış ve bu veri seti 119 dil ve lehçeyi kapsamaktadır. Veri toplama sadece web’den değil, aynı zamanda PDF benzeri belgelerden de yapılmıştır. Bu belgelerden metin çıkarmak için Qwen2.5-VL, çıkarılan içeriğin kalitesini artırmak için ise Qwen2.5 kullanılmıştır. Matematik ve kod verilerini artırmak amacıyla Qwen2.5-Math ve Qwen2.5-Coder ile ders kitapları, soru-cevap çiftleri ve kod parçacıkları gibi sentetik veriler üretilmiştir.
Ön eğitim süreci üç aşamadan oluşur:
- Aşama 1 (S1): 30 trilyondan fazla token ve 4K bağlam uzunluğu ile temel dil becerileri ve genel bilgi kazandırıldı.
- Aşama 2 (S2): STEM, kodlama ve mantık yürütme gibi bilgi yoğun verilerin oranı artırılarak ek 5 trilyon token ile eğitim yapıldı.
- Aşama 3: Yüksek kaliteli uzun bağlam verileri kullanılarak bağlam uzunluğu 32K token’a çıkarıldı.
Sonrası Eğitim (Post-training)
Hem adım adım düşünme hem de hızlı yanıt verebilen hibrit modeli geliştirmek için dört aşamalı bir eğitim hattı uygulandı:
- Uzun Zincir Düşünce (CoT) Soğuk Başlangıç: Modeller, matematik, kodlama, mantıksal akıl yürütme ve STEM gibi çeşitli görevleri kapsayan çeşitli uzun CoT verileriyle ince ayar yapılarak temel akıl yürütme yetenekleri kazandırıldı.
- Akıl Yürütme Tabanlı Pekiştirmeli Öğrenme (RL): Modelin keşif ve sömürü yeteneklerini geliştirmek için kural tabanlı ödüller kullanılarak RL için hesaplama kaynakları artırıldı.
- Düşünme Modu Füzyonu: Düşünme modeline, ikinci aşamada geliştirilen düşünme modeli tarafından üretilen uzun CoT verileri ve yaygın kullanılan talimat ayarlama verilerinin bir kombinasyonu üzerinde ince ayar yapılarak düşünmeme yetenekleri entegre edildi.
- Genel RL: Modelin genel yeteneklerini daha da güçlendirmek ve istenmeyen davranışları düzeltmek için 20’den fazla genel alan görevinde (talimat takibi, format takibi, ajan yetenekleri vb.) RL uygulandı.
Qwen3 ile Geliştirme ve Gelecek Vizyonu
Qwen3 modelleri (hem sonrası eğitilmiş hem de ön eğitimli versiyonları) Hugging Face, ModelScope ve Kaggle gibi platformlarda kullanıma sunulmuştur. Dağıtım için SGLang ve vLLM gibi framework’ler, yerel kullanım için ise Ollama, LMStudio, MLX, llama.cpp ve KTransformers gibi araçlar önerilmektedir.
Qwen ekibi, model mimarilerini ve eğitim metodolojilerini geliştirmeye devam ederek veri ölçeklendirme, model boyutunu artırma, bağlam uzunluğunu genişletme, modaliteleri çeşitlendirme ve uzun vadeli akıl yürütme için çevresel geri bildirimli RL’yi ilerletme gibi hedeflere ulaşmayı amaçlıyor. Modellerin eğitiminden ajanların eğitimine geçilen bir döneme girildiğine inanılıyor ve bir sonraki iterasyonun herkesin işine ve hayatına anlamlı ilerlemeler getirmesi hedefleniyor.
Qwen3’ü Qwen Chat Web (chat.qwen.ai) ve mobil uygulamasında deneyebilirsiniz!